



Almost every industry uses real-time data analytics solutions as well as real-time predictive analytics software, and there are lots of real-time big data use cases. This is especially true in e-commerce, sports betting, trading, custom marketing, and politics (where real-time updates on election results are a must).
According to a 2022 BARC survey of 2,396 users, analytics consultants, and vendors on data, business intelligence, and analytics trends, real-time data processing and analytics is among the top 10 trends in 2022. With the business world becoming increasingly data-centric and customer-centric, real-time data solutions are extremely beneficial, as they save time. With quick data processing, you can bring immediate value to customers.
Real-time analytics platforms minimize the time spent making decisions. They have to be capable of real-time big data processing to provide many users with timely insights and analytics. Existing analytics solutions rarely offer exhaustive data in an easy-to-view structure along with a personalized approach. But they really should!
Why should real-time data analytics solutions offer exhaustive data and a personalized approach?
There are lots of real-time analytics examples. Let’s consider Netflix, which collects information on customers’ searches, ratings, watch history, etc. As a data-driven company, Netflix uses machine learning algorithms and A/B testing to drive real-time content recommendations for customers.
This enables Netflix to provide customers with personalized suggestions, highlight content similar to what they’ve already watched, or advise titles from a specific genre. Thanks to such personalization, Netflix gains $1 billion a year in value from customer retention.
Examples of real-time analytics in logistics
The construction logistics company Command Alkon has implemented a real-time data analytics platform to efficiently manage the company’s data flow and generate critical business insights. This platform allows users to get relevant data on construction material deliveries in seconds, analyze that data, and build custom dashboards to track KPIs. Command Alkon’s team is constantly updating their solution to provide customers with even faster analytics capabilities.
Dashboards are a great way to visualize logistics data, and there are many modern solutions to create such dashboards. You can learn about them in our article on how dashboards are integral to supply chain visibility.
Example of real-time analytics in FinTech
The Canadian digital bank Scotiabank has also tapped into data analytics to offer more personalized services to their customers. With the help of data analytics technologies, the bank can reduce the time needed to generate customer offers from 14 days to a few hours. Plus, thanks to analytics insights, Scotiabank’s team has managed to better help thousands of customers manage their financial risks during the COVID-19 pandemic.
More personalized services encourage customers to stay loyal to your brand and interact more with your company.
If your idea is to build a comprehensive but simple tool capable of smooth real-time data processing, this introduction to a real-time data management system will give you a competitive advantage. Note that the tool you create will have to deal with big data. To begin this complete guide to real-time big data processing (supported by real-time big data processing examples), let’s define what exactly big data is.
Read also: Our data science expertise
Big data: a big deal for making optimal decisions
Big data refers to data sets so large that traditional data processing software can’t handle them. The emergence of big data happened gradually thanks to multiple favorable conditions.
Global digital transformation initiatives have encouraged the creation of data collection mechanisms that have made it possible to enlarge the number of data sources. Thus, it’s now possible to gather data from social media, online searches, electronic transactions, IoT-connected devices, RFID tags, and many more sources, making big data services essential for processing and analyzing this vast array of information.
Another aspect that enabled the proliferation of big data was the emergence of advanced data storage solutions. Cloud computing made it possible to store large data sets at a reasonable cost. Data repositories such as data lakes and data warehouses serve as cloud storage space for large and miscellaneous data sets. A single organization can make use of several data storage systems for different purposes and data types.
A data lake is perfect for big data, as it can store all types of data a company aggregates (data lake benefits). On the other hand, a robust enterprise data warehouse can store large amounts of structured data and serves as a single source of truth and single point of entry for the entire organization, enabling multiple data analytics capabilities.
Thus, just because data sets are large doesn’t necessarily mean that you’re dealing with big data. There are five characteristics, or five Vs, that indicate you’re working with big data.
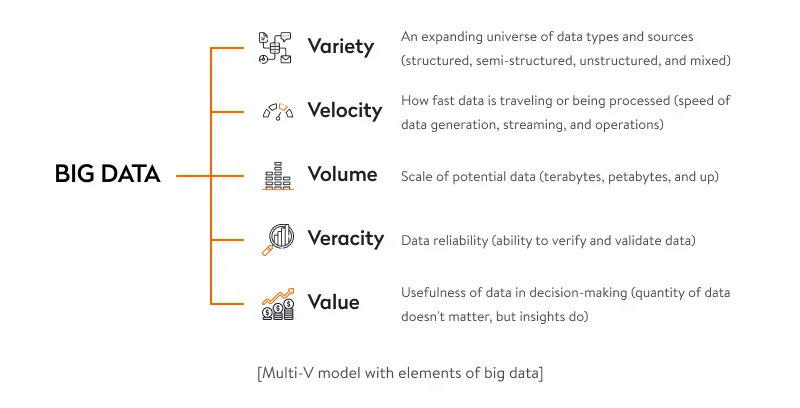
But extracting value from big data isn’t just about analyzing the data, which is a whole other challenge. It’s a comprehensive process that requires analysts and executives to find patterns, make logical assumptions, and predict the course of events. Learn how we developed software to handle big data for a 3PL company.
To simplify this process, you can use real-time big data analytics tools to reveal information regarding your processes, customers, market, etc. Real-time big data analytics involves pushing data to analytics and real-time predictive analytics software immediately when it arrives. Tools like Apache Storm and Apache Spark help businesses process big data. Let’s view the whole path data goes along to help you and your customers make data-driven decisions.
Real-time big data analytics
Analyzing big data in real-time entails collecting, streaming, processing, and serving data to identify patterns or trends. Real-time analytics is part of the larger concept of advanced data analytics solutions. In a previous article, we explain what advanced analytics is by comparing it with business intelligence using the example of the logistics domain. Let’s have a look at the image below to learn more about the process of real-time analytics.

Real-time data collection system
Depending on what data will be used for, the data collection process performed with the help of real-time data collection software may look different from one organization to another.
Where might data be taken from?
If your purpose is to help users make decisions based on highly specialized data, you’ll need to implement third-party integrations with data sources. If you want to analyze users to offer them personalized services, you’ll need to collect data on users and their behavior. Either way, your purpose is to optimize customer service processes.
Third-party integrations. To get data from APIs, we suggest using a crawler, a scheduler, and event sourcing. Employing data science services can further enhance the efficiency of these integrations by ensuring seamless data flow and advanced analytics capabilities. A crawler uses a scheduler to periodically request data from third-party APIs and records this data in a database. Event sourcing helps to automatically update data and publish events; it applies an event-centric approach to persistence: a business object is persisted by storing a sequence of state-changing events. If an object’s state changes, a new event is added to the sequence.
Customer data. You can collect customer data by asking users for it directly (for instance, when they subscribe). Technologies such as cookies and web beacons on your website can help you in monitoring visitors’ browsing histories. Social media, email, and company records on customers are also great sources to pull data from.
IoT-connected devices. Sensors installed in warehouses, trucks, banks, ATMs, or hospitals can generate lots of valuable real-time data. Triggered by any physical activity, they can collect and transmit data in real time that can immediately be used for analysis.
Read also: A guide to IoT testing
Three types of collected data
There are three types of data that are usually collected from cloud storage, servers, operating systems, embedded sensors, mobile apps, and other sources.
Structured data. This data is linear and is stored in a relational database (such as a spreadsheet). Structured data is much easier for big data tools to work with than are semi-structured and unstructured data. Unfortunately, structured data accounts for just a small percentage of modern data.
Semi-structured data. This type of data provides some tagging attributes. But it isn’t easily understood by machines. XML files and email messages are examples of semi-structured data.
Unstructured data. Nowadays, most data is unstructured. It’s mostly produced by people in the form of text messages, social media posts, videos, audio recordings, and so on. As this data is diverse (and partially random), it takes big data tools time and effort to make sense of it.
You might need to store past data to enable a user to compare it with real-time events. For example, a sports betting app might help users make bets based on old data by viewing analytics in a given year. A user might also be able to compare a specific type of data in the current period.
That’s why a database has to be capable of storing and passing data to a user with minimal latency. Databases must be able to store hundreds of terabytes of data, manage billions of requests a day, and provide near 100 percent uptime. NoSQL databases like MongoDB are typically used to tackle these challenges.
The data you collect then needs to be processed and sorted. Let’s discuss how this should be done.
Read also: How We Aggregated Customer Financial Data for a Wealth Management Platform

Real-time data streaming tools and technologies and data processing
There are two techniques used for streaming big data: batch and stream. The first is a collection of grouped data points for a specific time period. The second handles an ongoing data flow and helps to turn big data into real-time data.
Batch processing requires all data to be loaded to storage (a database or file system) for processing. This approach is applicable if real-time analytics isn’t necessary. Batching big data is great when it’s more important to process large volumes of data than to obtain prompt analytics. However, batch processing isn’t a must for working with big data, as stream processing also deals with large amounts of data.
Unlike batch processing, stream processing processes data in motion and delivers analytics results fast. This approach is often applied in solutions developed by a machine learning app development company to enable real-time insights. If real-time analytics solutions are critical to your company’s success, stream processing is the way to go. This methodology ensures only the slightest delay between the time data is collected and the time when it’s processed. Such an approach will enable your business to be transformed quickly if needed.

Read also: Our Expertise in Big Data and Analytics
You can use open-source tools to ensure the real-time processing of big data. Here are some of the most prominent:
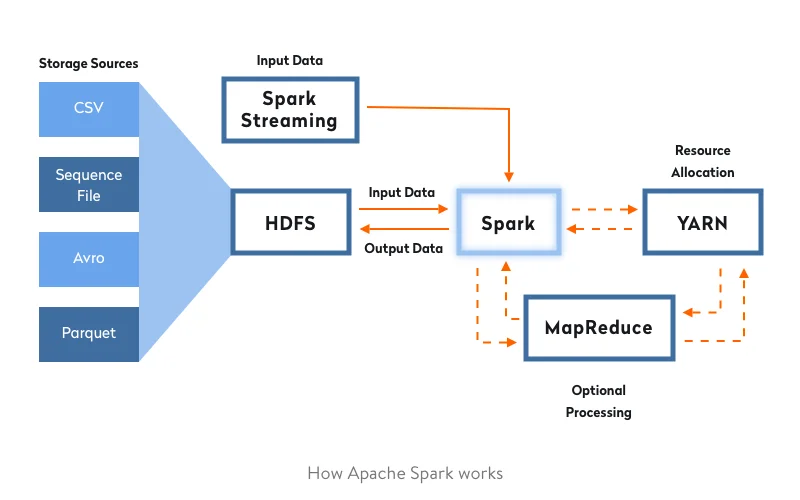
Apache Spark is an open-source stream processing platform that provides in-memory data processing, so it processes data much faster than tools that use traditional disk processing. Spark works with HDFS and other data stores, including OpenStack Swift and Apache Cassandra. Spark’s distributed computing can be used to process structured, unstructured, and semi-structured data. Furthermore, it’s simple to run Spark on a single local system, which simplifies development and testing.
Apache Storm is a distributed real-time framework used for processing unbounded data streams. Storm supports any programming language and processes structured, unstructured, and semi-structured data. Its scheduler distributes the workload to nodes.
Apache Samza is a distributed stream processing framework that offers an easy-to-use callback-based API. Samza provides snapshot management and fault tolerance in a durable and scalable way.
World-recognized companies often choose these well-established solutions. For example, Netflix uses Apache Spark to provide users with recommended content. Because Spark is a one-stop-shop for working with big data, it’s increasingly used by leading companies. The image below shows the principle of how it works:
You can also opt for building a custom tool. Which way you should go depends on your answers to three how much questions:
– How much complexity do you plan to manage?
– How much do you plan to scale?
– How much reliability and fault tolerance do you need?
If you’ve managed to implement the above-mentioned process properly, you won’t lack users. So how can you get prepared for them?
Real-time big data analytics architecture
In this section, we discuss the most convenient architecture type for real-time big data analytics. A set of Amazon Kinesis services that includes Amazon Kinesis Data Streams, Amazon Kinesis Data Firehose, and Amazon Kinesis Data Analytics can be helpful in building a custom data analytics architecture.
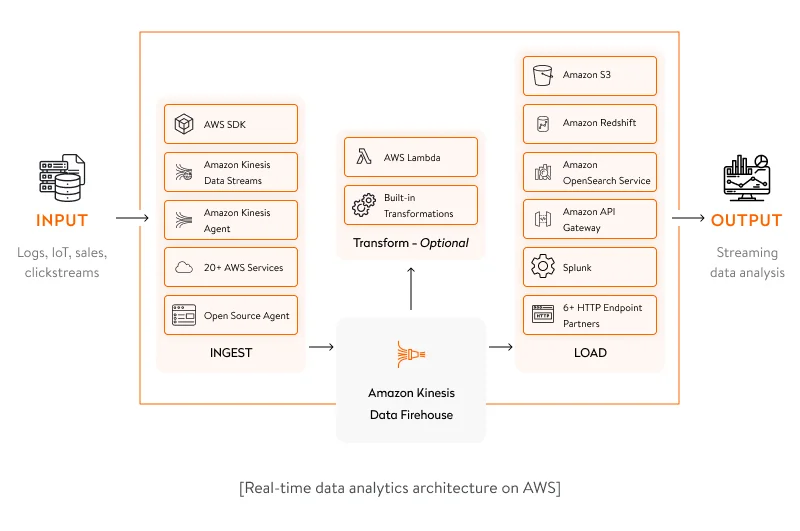
Amazon Kinesis Data Streams is a service for capturing, processing, and storing data streams of any scale. It’s suitable for software solutions that generate high-frequency real-time data and allows for processing this data in seconds.
Amazon Kinesis Data Firehose is an extract, transform, and load (ETL) tool that can capture real-time data, process it, and transfer it to different data storage systems such as a data warehouse (Amazon Redshift) or a data lake (Amazon S3), or directly to analytics services. This tool also allows for efficient monitoring of the security of real-time networks and creating alerts on possible cyber threats.
Amazon Kinesis Data Analytics is an Amazon service that allows for real-time data analytics with the help of Apache Flink. It provides flexible APIs in programming languages including Java, Scala, and Python. With the help of prebuilt analytics capabilities, you can build a robust streaming application literally in hours.
Developing a serverless architecture is one of the most suitable solutions to properly combine all of the abovementioned Amazon services for real-time analytics. For businesses considering this approach, collaboration with experienced artificial intelligence consultants can ensure efficient design and deployment of the solution architecture. A serverless architecture means the absence of any infrastructure that you’ll need to manage as well as huge automatic scaling capabilities.
For building a serverless architecture, it’s worth using AWS Lambda as the logic layer of the application. AWS Lambda is an event-driven computing service that can process thousands of events per second. It helps you develop highly scalable and high-performance software solutions.
A real-time analytics architecture has many benefits, but the most critical are high-load capabilities and scalability thanks to implementing real-time analytics.
Read also: How We Implemented a Data Lake for a Manufacturing Company
High load capabilities and scalability provided by big data and real-time analytics
A properly developed system might attract lots of users. So make sure it will be able to withstand high loads. Even if your project is small, you might need to scale.
What is a high load?
- A high load starts when one server is unable to effectively process all of your data.
- If one instance serves 10,000 connections simultaneously, you’re dealing with a high load.
- A high load is simultaneously handling thousands or millions of users.
- If you deploy your app on Amazon Web Services, Microsoft Azure, or Google Cloud Platform, you’re automatically provided with a high-load architecture.
Principles of building apps capable of handling high loads
Dynamics and flexibility. When building large-scale apps, your focus should be on flexibility. With a flexible architecture, you can make changes and extensions much more easily. This means lower costs, less time, and less effort. Additionally, using the Principle can aid in prototyping user interfaces, allowing for early testing and refinement of design concepts. Note that flexibility is the most essential element of a fast-growing software system.
Scalability. Businesses should tailor scalability to their development purposes, meaning in accordance with the number of expected users. Make sure you carry out preliminary research to ensure your app is scalable enough to meet the expected load. The same applies to the app architecture. Keep in mind that scalable products are the foundation of successful software development.
Scaling any app involves four steps:

If you’re building a new app, it isn’t necessary to immediately ensure an infrastructure capable of dealing with millions of users and processing millions of events daily. But we suggest designing your app to scale from the outset. This will help you avoid large-scale changes in the long run.
We also recommend using the cloud to host new projects, as it reduces server costs and improves management.
In addition, lots of cloud hosting services offer private networks. These services enable developers to safely use multiple servers in the cloud and make systems scalable.
The following are some tips to create scalable apps:
Choose the right programming language. Erlang and Elixir, for example, ensure actor-based concurrency out of the box. These languages permit processes to communicate with each other even if they’re on different physical machines. As a result, developers don’t have to worry about the underlying network or the communication protocol used.
Ensure communication between microservices. The communication channel between your services should also be scalable. To accomplish this, you can apply a messaging bus, which is infrastructure that helps different systems communicate by means of a shared set of interfaces. This will allow you to build a loosely coupled system to scale your services independently.
Avoid a single point of failure. Make sure there’s no single resource that might crash your entire app. To ensure this, have several replicas of everything. We suggest running a database on multiple servers. Some databases support replication out of the box — for instance, MongoDB. Do the same with your backend code, using load balancers to run it on multiple servers.
Role of databases in handling high loads
Traditional relational databases are not tailored to benefit from horizontal scaling. A new class of databases, dubbed NoSQL databases, take advantage of the cloud computing environment. NoSQL databases can natively manage the load by spreading data among lots of servers, making these databases fit for cloud computing environments. To gain more insights on what to consider when choosing a database, read our detailed guide.
One of the reasons why NoSQL databases can handle high loads is that related data is stored together instead of in separate tables. Such a document data model, used in MongoDB and other NoSQL databases, makes these databases a natural fit for cloud computing environments (types of data models).
To ensure the high load capacity of our client’s World Cleanup Day app, we used PostgreSQL, which provides simultaneous I/O operations and handles high loads. Check out our case study for details.
As a result of the above-mentioned implementations and the use of big data technology described in this guide, you’ll be able to provide users with software for deep analytics and reporting that processes and visualizes data collected from multiple sources in real time. Yalantis is experienced in the complete lifecycle of developing mobile- and web-friendly real-time analytics solutions: collecting data from several sources, building attractive charts, and displaying projections (lifecycle data management). We’ll gladly help if you’re interested in big data consulting and developing big data infrastructure.
Have a big data project in mind?
Why not discuss it?
FAQ
What is real-time data analytics?
Such analytics is the instant analysis of structured and unstructured data that enables prompt and informed decision-making. This type of analytics helps organizations enhance tracking and evaluating the levels of risk, ensure personalization, detect scams, and provide business intelligence.
What is real-time data processing?
It’s processing of an unlimited influx of data, with very short latency requirements for processing — measured in milliseconds or seconds.
What is a real-time analytics platform?
Such a platform helps companies take full advantage of real-time data by enabling them to extract meaningful and actionable insights and trends from it. By using such platforms, you can analyze information from the business point of view in real time.
About the author




