|
Key takeaways
|
A few months ago, our data experts spoke with the CTO of a mid-sized logistics company. They had recently hired a Chief Data Officer (CDO), revamped their BI tooling, and invested heavily in the cloud infrastructure. “We’ve done everything by the book,” the CTO said. “But somehow, we’re still not making decisions based on data.”
This CTO isn’t alone. The Data and AI Leadership Executive Survey by NewVantage Partners revealed an interesting discrepancy: while nearly 74% of companies have hired a CDO or Chief Analytics Officer (CAO), only about 26% say they’ve actually become data-driven.
These findings prove that appointing a CDO or CAO still doesn’t guarantee that a company will become data-driven. Without a reliable foundation for storing, managing, and accessing enterprise data, even the most skilled leadership can’t drive meaningful transformation. One of the core reasons companies struggle to become data-driven is the lack of a centralized, well-structured data environment. That’s why building an enterprise data warehouse (EDW) is a critical step.
In this post, we cover:
- what’s an EDW
- why you need it
- how you can benefit from it
- a detailed step-by-step process on how to build a data warehouse for your enterprise needs.
What is a data warehouse vs. an enterprise data warehouse (EDW)?
In this section, let’s see how a data warehouse differs from an enterprise data warehouse and whether you need one or another.
Data warehouse definition or why databases aren’t enough
A data warehouse is an architecture design approach to organize the efficient storage of large amounts of structured data to enable data analytics and drive data-driven decision-making. By efficient storage, we mean storing only those datasets that are relevant for a particular business. For instance, instead of storing a total number of sales transactions, it might be better for an e-commerce company to store the total sum of sales over a certain period. The latter datasets provide more value and can give insights on how a business performs and whether they fulfill their financial goals.
Why is a data warehouse better than simply retrieving data for analysis from different application databases? Databases store transactional data, which is regularly updated. So if, for instance, you’re interested in analyzing your sales metrics over five years by merely extracting this data from application databases, you’ll never find it there. Whereas a data warehouse can store large amounts of data available for historical data analysis at any time.
EDW definition
Computer scientist B. Inmon introduced enterprise data warehouse design. Let’s take Inmon’s definition of an EDW from his book “Building the data warehouse”: An EDW is a subject-oriented, integrated, time-variant, non-volatile collection of data in support of management’s decision-making process. It’s the data footprint of your business processes.
With the help of an EDW, it’s possible to set your own terms for data aggregation, data granularity, and data partitioning. To make sense of these structured datasets and derive actionable insights, companies often turn to business intelligence services. You can define different datasets’ low (more detailed) or high (less detailed) granularity criteria. And for optimized data storage, you can also partition datasets into smaller ones. To effectively implement such tailored data strategies, many enterprises rely on professional data science development services to enhance data management and analytics capabilities.


Difference between a data warehouse and an EDW
A data warehouse is a broad term that refers to a centralized system for storing large volumes of structured data. Think of it as a general-purpose data storage solution that can support various analytical and reporting needs, depending on how it’s designed and used.
An enterprise data warehouse (EDW), on the other hand, is a specific type of data warehouse centered around business processes and decision-making needs. In this approach, it’s your enterprise goals, operational workflows, and analytics requirements that shape what data is collected, how it’s transformed, and how it’s stored.
In short:
- A data warehouse is the toolbox.
- An EDW is a tailored solution built using that toolbox to serve your enterprise’s specific data analytics needs.
Benefits of the enterprise data warehouse
- Structured data management. Enterprise data warehouse services allow organizations to implement a structured approach to data storage and, as a result, data analysis. In simple terms, with a clear request, you can quickly find any data you need in an EDW.
- Centralized access control. With an EDW, you won’t need to maintain multiple data access policies. Once all of your enterprise data is consolidated in the EDW, you’ll only need to manage access rights to it.
- Faster and more accurate reporting and analytics. Collecting different data from scattered corporate databases complicates and significantly prolongs report generation. Thus, data analysts can potentially make mistakes during this process. With an EDW, analysts can quickly access necessary (and, most importantly, accurate) data to generate correct and efficient reports.
- High data quality. Since data in an EDW is normalized and transformed for future analysis, there’s minimal data duplication, and consequently, data analysts need less time to generate quality reports.
Compare life with an EDW to life without:
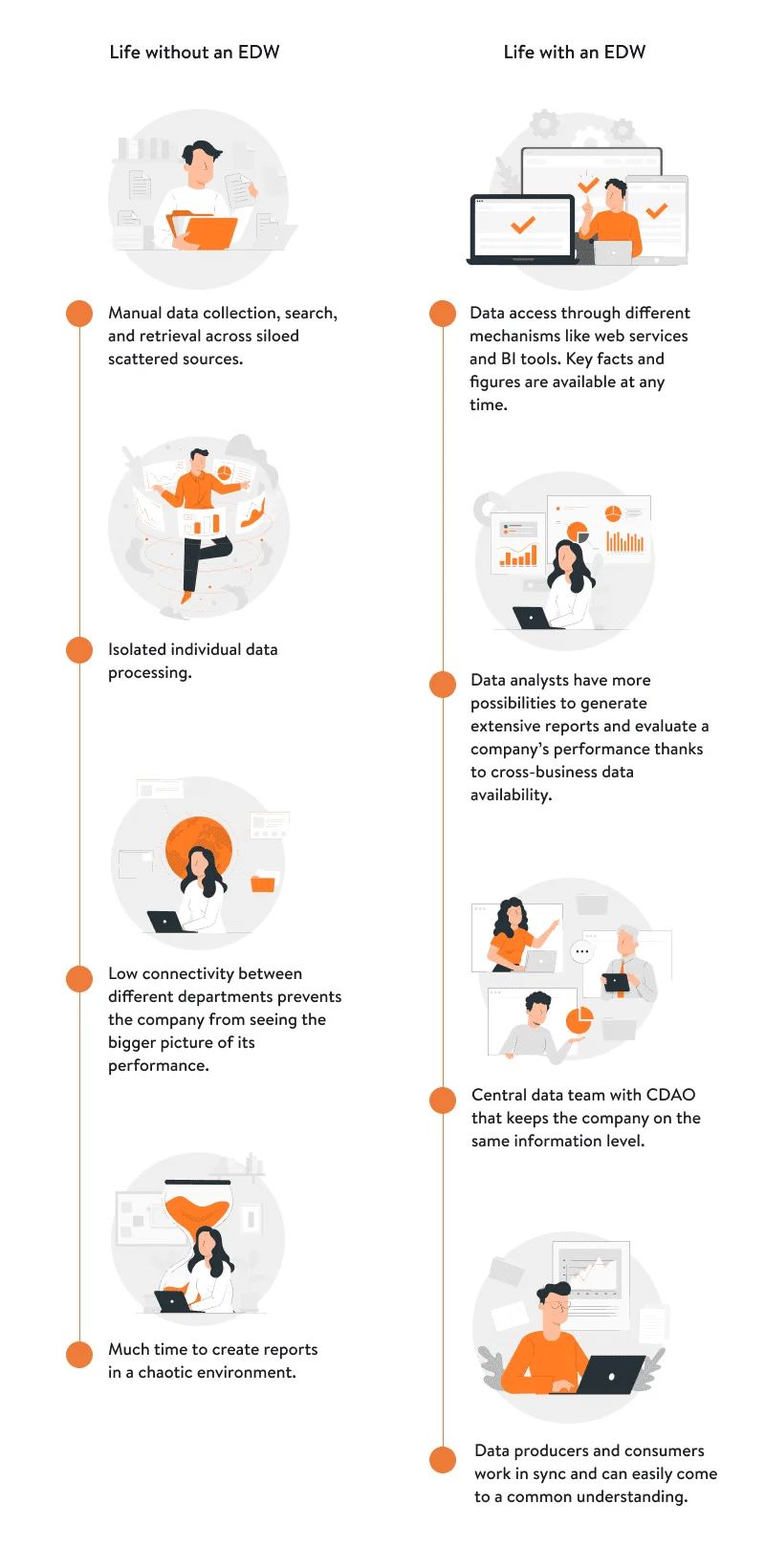
The above infographic shows that implementing an enterprise data warehouse is an opportunity to take a step further in becoming a data-driven organization. You’ll know how to manage your enterprise data and which specific datasets to analyze to make accurate decisions that impact your business performance.
Continue reading to learn about building a data warehouse from scratch. A digital warehouse can become an end-to-end business solution through chaining all of the relevant corporate data sources.
Real-life adoption of an EDW
The first and biggest reason for building a data warehouse from the get-go is to make it perfectly fit your current business model. Especially if your company is large and you need to keep track of the data flow across multiple departments or even facilities like a hospital network. It’s worth mentioning that an EDW can be part of your bigger enterprise data management projects.
For example, a large Helsinki University Hospital (HUS) with more than 17 hospital locations has incrementally adopted enterprise data warehouse solutions as part of a much bigger project called a “big data platform.” The company needed a single source of truth for structured data, like financial data, and unstructured data, like medical images. You can also learn how we’ve helped the US 3PL company generate more insights and better manage a big data flow thanks to our big data analytics solution.
At the initial phase of this project, they developed an EDW to collect and store structured data. Thus, an EDW turned out as an essential building block of a much bigger enterprise-wide data platform. And that’s one of the additional benefits of an enterprise data warehouse, as it can integrate with other data repository solutions in your organization, such as a data lake, to form a unique data platform that perfectly fits your business needs. Since the initial implementation of its EDW, HUS has been gradually expanding this data platform to fit its changing business environment better.
Read also: Central data repository
Tired of scattered data and slow, inaccurate reports? Let’s build a single source of truth to end the chaos and streamline your analytics.
Types of enterprise data warehouses
Depending on the hosting environment, enterprise data warehouses can be on-premises, cloud, or hybrid. Your long-standing analytical goals, the data volume, and hardware and software capabilities define this choice, and many other not-so-obvious factors. For instance, if you choose to migrate your entire infrastructure to the cloud without first analyzing your data technologies, hidden costs, and time constraints, it may be a disaster for your business.
So, it’s best to carefully choose your hosting environment by thoroughly analyzing available resources with a competent data team and by breaking down your potential ROI from investing in a particular environment.
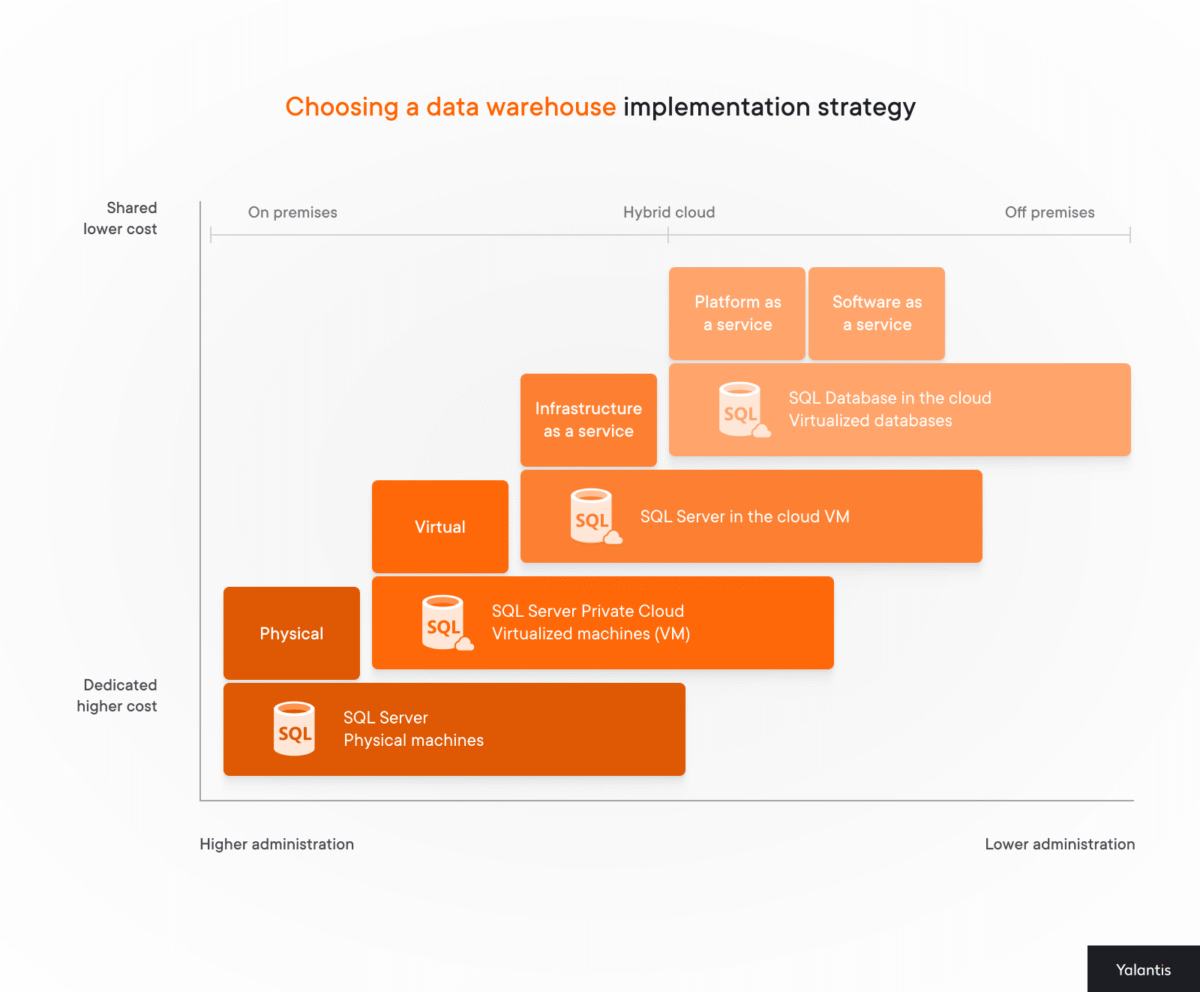
In this section, we cover each enterprise data warehousing type in detail and explain the below diagram, which indicates that moving from on-premises to cloud means decreasing administrative overload and maintenance costs, but it’s not that simple. Let’s learn why.
On-premises EDW
Rolling out an enterprise data warehouse on-premises can be a cost-intensive yet reliable option to keep your sensitive business data safe. A data classification strategy can help you categorize your data according to sensitivity, business value, and regulatory requirements. And based on the findings, you can analyze how critical it is for your enterprise to store data in the on-premises enterprise data warehouse.
Key benefits of keeping your data on-premises are:
- Full ownership of the data infrastructure. An on-premises EDW is built on top of your proprietary hardware and software components, which makes your team the only owner of the EDW. This allows you to customize, update, and change your EDW to the extent that your business needs at the current moment.
- Maximum control over data governance. On-prem gives you full authority over who accesses what and how. You can implement granular security policies and monitor everything internally, which is especially useful in industries with strict data processing and sharing rules.
- No dependency on internet connectivity. Your system stays up and running even during outages or service disruptions, which is crucial for operations that can’t afford downtime, such as manufacturing floors, critical healthcare systems, or real-time financial processing.
- Support for custom or legacy systems. If your enterprise relies on legacy applications or highly specific system configurations, on-prem may be the only way to support these seamlessly, without needing to re-architect for the cloud.
Go with on-prem if you:
- handle highly sensitive or regulated data
- already have robust IT infrastructure in place
- need tight control over performance, uptime, or configurations
- are not ready (or allowed) to put certain datasets in the cloud
Cloud EDW
Hosting a data warehouse in a cloud environment can fall into three categories:
- Infrastructure as a Service (IaaS). A cloud vendor handles the entire infrastructure (hardware part). You get a virtual machine (VM) or a virtual data warehouse in the cloud where you install and manage your own server, just like you would on a physical server in your office, but without buying or maintaining the hardware.
- Platform as a Service (PaaS). PaaS takes it a step further. The cloud provider manages both the hardware and the operating system. You focus only on building and running your applications or databases; no need to worry about patches, OS updates, or system-level setup.
- Software as a Service (SaaS). Even more abstracted, ideal for teams who just need a ready-to-use solution. You’re not setting up EDW databases at all. Instead, you might use a BI platform like Power BI or Looker, where everything is ready out of the box: data connectors, visualizations, user permissions, etc.
Implementing a data warehouse in the cloud is a common approach, as it has several advantages:
- Ready solutions. A cloud environment is already established and requires only scaling, configuration, and customization to align with your goals.
- Elasticity. Depending on your business needs, you can either expand storage space or decrease it, and such manipulations won’t require big investments, unlike with an on-premises environment.
- Horizontal integration with different services. Cloud services easily integrate with other solutions. For example, cloud storage solutions can integrate with cloud solutions for data analysis.
- Reduced IT overhead costs. For an on-premises implementation, you have to maintain a large IT team to be in charge of all hardware and software. To maintain a cloud data warehouse, you need significantly fewer people.
- Lower capital expenses and minimal operating expenses. This benefit is the ultimate result of all the above-mentioned benefits. To implement a cloud-based data warehouse solution, you don’t have to purchase any expensive hardware or software. You spend as you go and keep your budget flexible.
All of the major cloud providers offer solutions for data management, positioning themselves as enterprise data warehouse vendors. We would like to point out Amazon Web Services (AWS) and, in particular, Amazon Redshift. Redshift is a service specifically designed for data warehousing. Its biggest advantage is integration with a data lake for diverse use cases of data lake, allowing you to ensure a seamless information flow across the whole enterprise in real time. Amazon Redshift provides vast data analytics capabilities and introduces a whole new notion — a data lakehouse. The data lakehouse combines data from your data lake and a data warehouse, allowing you to achieve new heights in enterprise data analytics.
Even though the benefits of cloud computing sound compelling, there’s still a question: Is it secure enough to store data in the cloud? The answer is a definite “yes.” Cloud services provide reliable data encryption mechanisms that encrypt data during transfer and storage. And the keys used to decrypt the data stored outside the cloud environment. This way, cloud services provide a high level of data protection even for the most sensitive data.
Vendors of cloud data warehousing services also meet most common compliance requirements. For instance, AWS and Microsoft Azure meet the requirements of HIPAA, PCI DSS, ISO 27001, and FedRAMP.
Read also: Secure application development from planning to production
Go with the cloud if you:
- want to minimize upfront investment
- need to scale quickly
- don’t want to manage hardware
- use a wide range of integrated cloud services (BI tools, AI/ML platforms)
- are comfortable with external data hosting and encryption standards
Hybrid EDW
A hybrid enterprise data warehouse combines the best of both worlds — the control and security of on-premises infrastructure with the scalability and cost-efficiency of the cloud. For many enterprises, this enterprise data warehouse strategy offers the flexibility needed to handle a mix of sensitive, regulated data and fast-growing, analytics-ready datasets.
For example, you might store sensitive customer or financial data in your on-premises systems for full control and compliance, while using the cloud to store operational or historical business data for on-demand analytics and long-term storage. With the right setup, the two environments work together seamlessly, allowing for efficient data movement, integration, and access.
The strategy diagram you saw earlier illustrates exactly this balance: as you move from physical servers (left) to full cloud solutions (right), administration overhead decreases while shared infrastructure and cost flexibility increase. Hybrid sits right in the middle, letting you decide what stays under your roof and what moves to the cloud based on data classification, business priorities, and compliance needs.
Key benefits of a hybrid EDW:
- Flexibility in data placement. Keep sensitive workloads on-prem while leveraging cloud elasticity for analytics or long-term storage.
- Optimized resource usage. Prioritize infrastructure investment only where it matters most.
- Scalable analytics environment. Use cloud computing power for data processing, machine learning, or real-time dashboards without overloading on-prem servers.
- Improved resilience. A hybrid EDW architecture can offer built-in redundancy and disaster recovery by splitting systems across cloud and physical environments.
Go hybrid if you:
- are transitioning from legacy systems to the cloud and need a gradual migration path (for instance, migration to microservices)
- operate in a regulated industry but want to use modern analytics tools not supported on-prem
- manage data across multiple sources and regions with local residency laws
- want to test cloud capabilities without a full migration or lock-in
- want to extend rather than replace your existing infrastructure which still holds value for your business
You should make your choice of the implementation environment based on your business and industry needs and requirements. But cooperating with an expert data team or a data engineering services agency can save you from a lot of potential financial losses.
A data team can help you break down your existing data infrastructure into separate components that are critical in making the right decision about choosing a data warehouse hosting environment. Such components can include data technologies, analytical capabilities, transactional databases, ETL processes, and data types (structured, semi-structured, and unstructured). Expert data specialists know how complicated and multi-faceted this decision can be and can indicate hidden pitfalls that weren’t top of mind for you. Only a holistic approach can help you make a wise decision with a high potential ROI.
Building an enterprise data warehouse step-by-step
Implementing a data warehouse is, luckily, a gradual process like digital transformation and doesn’t require you to make huge investments at once. Below is a list of steps you should take along with your IT engineers as part of the full-cycle custom development process to successfully build a data warehouse step-by-step and implement it into your daily workflow. Further, we’ll discuss some of the most crucial elements from this list in greater detail.
Step 1. Define business requirements
Drawing on your business needs, compose a detailed list with prioritized functional and non-functional business requirements, as they will impact your choice of data warehousing solutions. For instance, if your business environment is constantly changing, then one of your non-functional requirements should be flexibility. If in the near future you want your company to change and grow, your priority should be scalability. Consider working with a skilled solution architect to properly define and handle your business requirements. Read our blog article to find out how a skilled architect can do this.
Step 2. Analyze source data
To make sure you’ll load only relevant and accurate data into your data warehouse, you should define all available data sources. It’s also important to determine systems of record to avoid loading unnecessary datasets, as certain data may be part of a few storage systems. For example, sales order information can be streamed from your order management system (OMS) to logistics software for your operational needs. Still, the OMS remains your source of truth, as logistics software may manipulate the data and distort potential insights.
Step 3. Build conceptual, logical, and physical data models
After you’ve defined your business requirements, it’s time to build a preliminary enterprise data warehouse model, as it will help you schematically visualize your key business processes, meaning your business entities and the way they interact with each other. It’s crucial to build those models with the support of domain experts, as each industry has specific business processes.
A conceptual data model is necessary to establish clear relationships between the main business entities (concepts) to define an enterprise’s information needs. For example, a supply chain company may distinguish business entities including shippers, carriers, suppliers, products, orders, customers, and manufacturers.
A logical data model is a detailed version of a conceptual model. The logical model provides attributes (columns) related to a certain business entity, such as a carrier’s country for a carrier entity.
A physical data model is even more detailed, as it adds more attributes to entities like primary and foreign keys. A primary key is a unique identifier, and there can be only one in a table; a foreign key is created to link two tables (entities). Practically speaking, a foreign key is a primary key from one table inserted into another.
You need to ensure that your EDW data model can be easily adjusted as your business evolves. Business changes may cause significant updates to the data landscape, so involving a qualified information architect is necessary to make sure the data model is flexible enough.
Step 4. Identify and build a data warehouse schema
This step is a logical continuation of the previous. Once you have clear models of your business processes, you can proceed with arranging your final and detailed version of data modeling projects — the physical model — into a data warehousing schema. There are many types of schemas and methods to generate them automatically. Your software architect can help you choose the best approach on how to set up a data warehouse for your needs. To give you an overall understanding, we’ll review a few of them in the next section — in particular, the star schema, snowflake schema, and data vault schema.
Step 5. Incrementally implement a data warehouse architecture
With a fitting data warehouse schema, you can compose an enterprise data warehouse system. There are several types of enterprise data warehouse architecture approaches. Go on reading to find out which you can choose and how to create a data warehouse.
From defining requirements to implementing architecture, we handle the entire end-to-end process of building your custom enterprise data warehouse.
Enterprise data warehouse components, schemas, and architecture designs
Key components of the EDW design
Below are common components that can be included in the enterprise data warehouse but not all of them are mandatory and some can be customized based on business requirements.
- Data sources. Coming from various operational data stores like ERP, CRM, SCM, and external data feeds, these sources provide the raw data ingested into the EDW.
- Staging area. A temporary storage space where data is collected and pre-processed. This layer ensures data is cleansed and transformed appropriately before loading into the warehouse.
- ETL/ELT processes. Responsible for data extraction from sources, transforming it into a suitable format, and loading it into the warehouse. ELT variations load data first and then transform it within the warehouse environment.
- Data warehouse storage. The central repository where integrated, historical, and subject-oriented data is stored. This storage is optimized for query performance and analytical processing.
- Metadata repository. A data warehouse component that stores information about the data’s origin, structure, and transformations. Metadata facilitates data governance, lineage tracking, and enhances user understanding of the data assets.
- Data marts. Subsets of the data warehouse tailored for specific business departments, enabling focused analysis and reporting.
- Online analytical processing (OLAP) cubes. Multidimensional data structures that allow for complex analytical queries, such as trend analysis and forecasting, by pre-aggregating data for faster retrieval.
- Access tools and APIs. Interfaces and tools that enable users to interact with the data warehouse, including BI tools, dashboards, and APIs for custom applications.
- Data security and governance layer. Mechanisms to ensure data privacy, compliance, and integrity. This includes role-based access controls, encryption, and audit trails.
- Monitoring and management tools. Enterprise data warehouse tools oversee the performance, availability, and health of the data warehouse, ensuring optimal operation and quick issue resolution.
Data warehouse schemas
There are three data warehouse schemas: the star schema, snowflake schema, and data vault schema. A schema establishes relationships between datasets in a data warehouse to make them ready for querying and further analysis.
However, certain companies choose not to build any schemas but rather compose a set of flat tables for loading multiple data columns into one table. This approach doesn’t take into account data granularity and the difficulty of making changes to tables. Therefore, schema designs have appeared, as they provide more flexibility and a better data structure.
Star schema
This is the most common and traditional way to build a data warehouse. A star schema consists of fact and dimension tables. To better understand how it’s built and its purpose, let’s take as an example a typical star schema for a healthcare company.
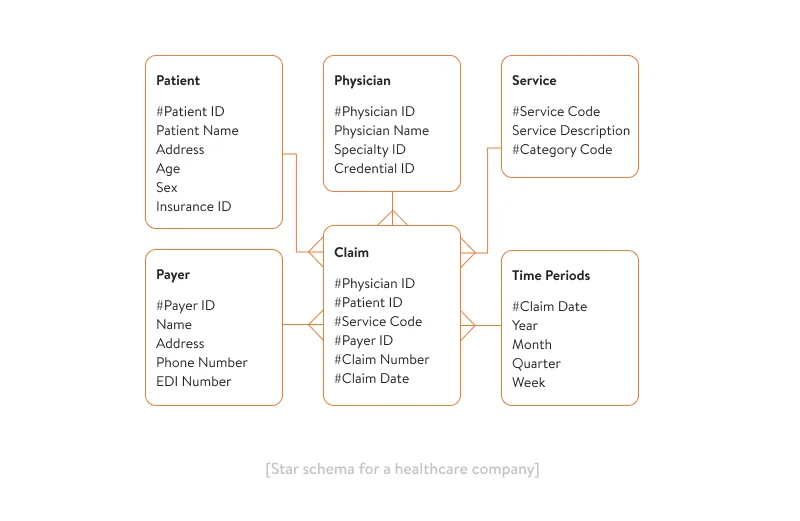
The table in the middle is a fact table that contains keys to define each dimension table. Each dimension table, in turn, contains dimension attributes. For example, a dimension table for a patient may consist of such attributes as patient name, address, age, sex, and insurance ID.
Pros of a star schema:
- Easy to design and set up due to the simple relationship between datasets
- Data analysts can quickly query data thanks to simplified join logic between the fact table and dimension tables
Cons of a star schema:
- Less flexibility compared to other schemas and not suitable for complex analytical queries
- High rate of data redundancy and duplication
Snowflake schema
Another type of data warehousing schema is the snowflake schema. In practice, the snowflake schema is an enhanced and normalized variant of the star schema. The snowflake schema also contains fact tables, but its dimension tables get split into multiple additional dimension tables. Let’s take the same example of a healthcare star schema and transform it into a snowflake schema.
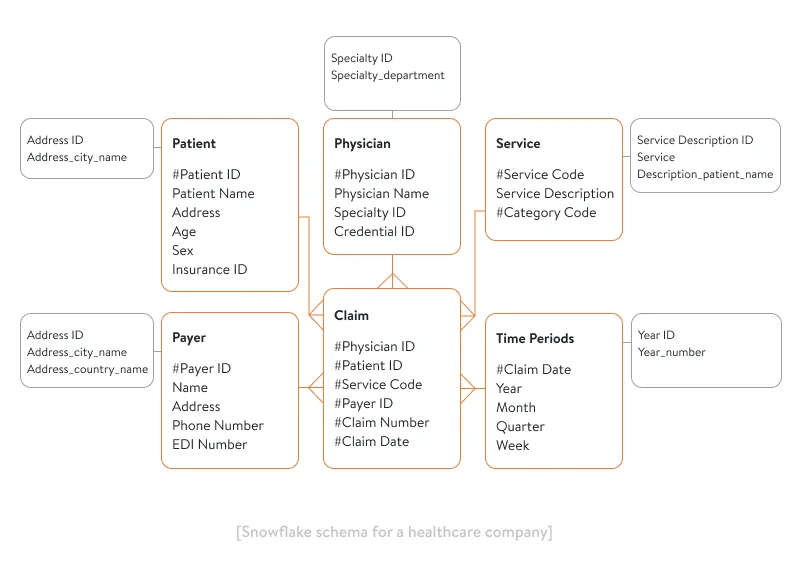
We’ve made a very simplified snowflake schema, but it still shows its essence. We’ve only added one additional dimension table to each of the initial tables, but there can be more than one. That’s why a snowflake schema can become rather complex.
Pros of a snowflake schema:
- Eliminates data redundancy and duplication, as each dimension attribute gets its own table and won’t get mixed up with similar attributes
- Provides more data analytics possibilities than a star schema due to more elaborate relationships between datasets
Cons of a snowflake schema:
- Harder to design and maintain snowflake schemas compared to star schemas
- Complex arrangement of datasets within a snowflake schema complicates data queries, making them take longer than with a star schema
Data vault
A data vault is a hybrid approach to data warehouse design that combines the best of the star schema and the third normal form (3NF) (another type of normalized data schema). Data vault inventor Dan Lindstedt says that a data vault is perfectly suitable for modern enterprise data warehouse solutions. Currently, the most recent version is data vault 2.0.
A data vault 2.0 contains raw and business vaults; a raw vault keeps all the raw data within the enterprise along with data duplicates, while the business vault is a layer on top of the raw vault that consists of business rules and calculations. The raw vault consists of three components:
- Hubs are entities that include business keys (one key is used to identify one record). If there is no direct business key available, hubs also have surrogate keys to identify their data objects.
- Links are connectors between different hubs and build relationships between business keys.
- Satellites are descriptive tables associated with hubs. Each hub or link may have one or more child satellites. Satellites also contain metadata linking them with their parent hub or link.
Hubs and links are more structural elements of a data vault model, while satellites provide context for the business processes captured in the hubs and links. The data vault is a more complex and scalable model than the star and snowflake schemas. Below is a simplified example of customer and order data distribution in the data vault model.
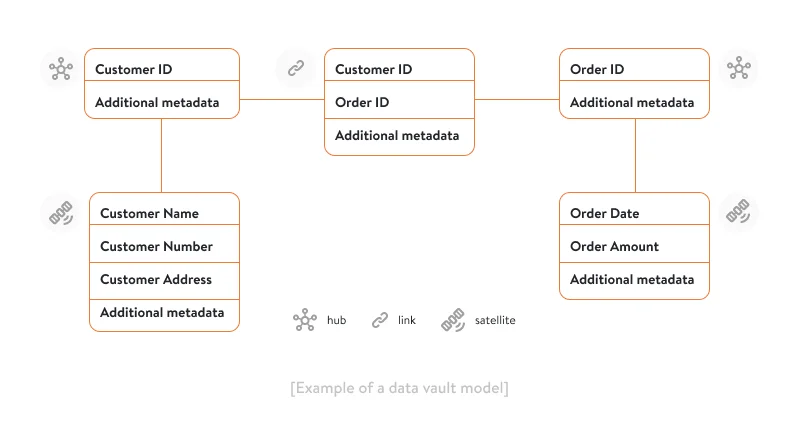
Pros of a data vault:
- Flexible and scalable in terms of adding or removing data sources (can scale to hundreds of terabytes or petabytes)
- Quick and easy to automate an ETL process with a data vault and simultaneously download data to hubs, links, and satellites
- Data vault modeling technique allows for spotting business issues that weren’t obvious before thanks to multiple data joins
Cons of a data vault:
- Not suitable for static data with little to no changes
- Not optimized for smooth query performance and often requires building data marts on top as a presentation layer
To make the right choice of data warehousing tools, you should consider the technology stack and the tools you’ll use to analyze data. For example, the Tableau business intelligence tool works with simple flat tables, as it’s hard for this system to process many data joins as in star and snowflake schemas. Power BI can easily process star schemas.
The data warehouse development process is incremental and ongoing. According to Inmon, it can look the following way:
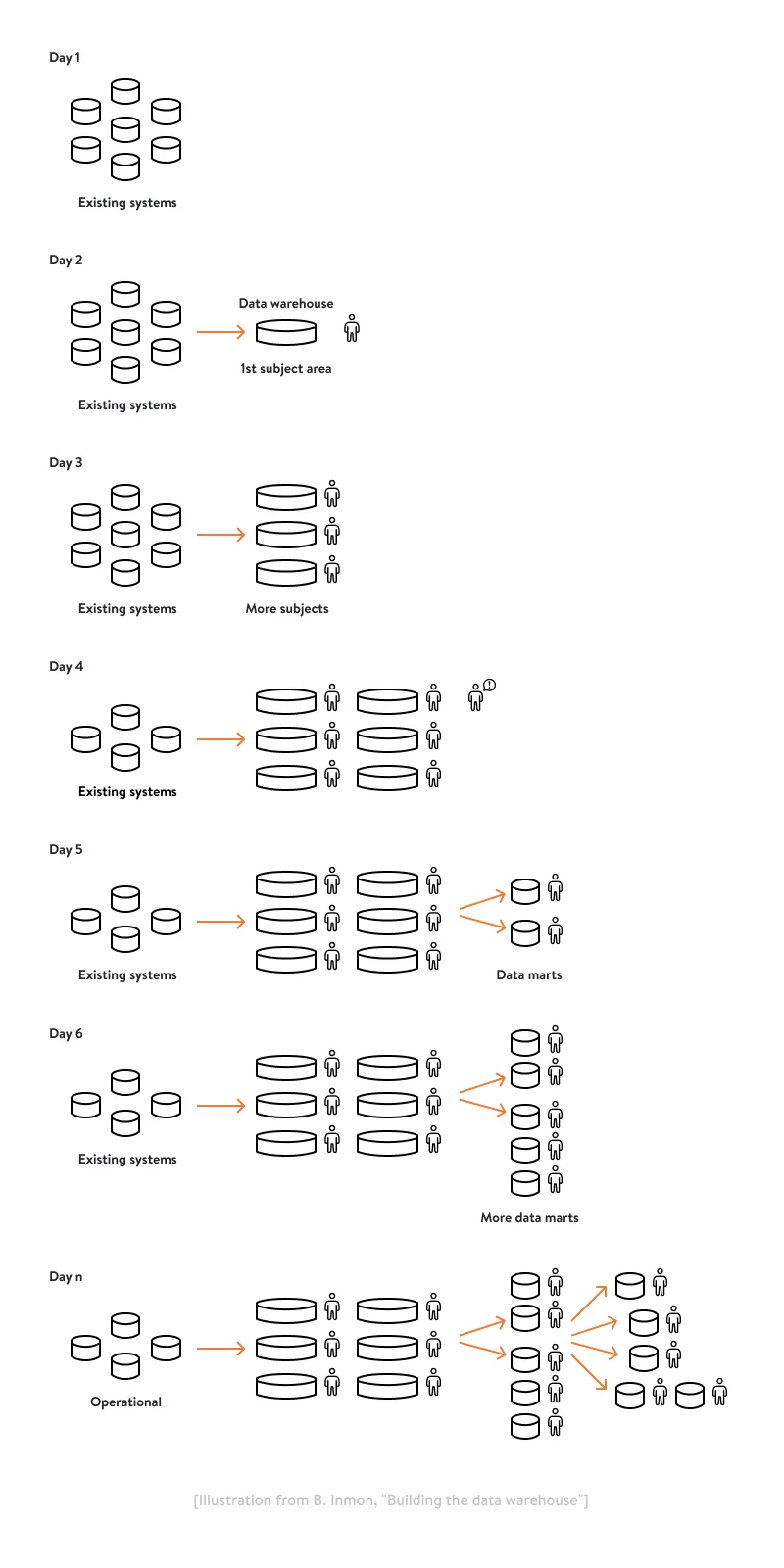
This process doesn’t necessarily happen in a matter of days, and the above schema is rather simplified and sped up. At first, you implement one subject area for your data warehouse and have a small number of analysts who can use this data for reporting purposes.
Then, you add more subject areas and more people get access to data. Afterward, you start building a few data marts on top of your EDW to organize data use and achieve more purposeful data queries. After that, you can scale even further with more data marts and data consumers. All in all, you scale your EDW as long as your business scales, your data volume grows, and your information needs across the enterprise increase.
The above schema by Inmon can be split into three data warehouse development strategies:
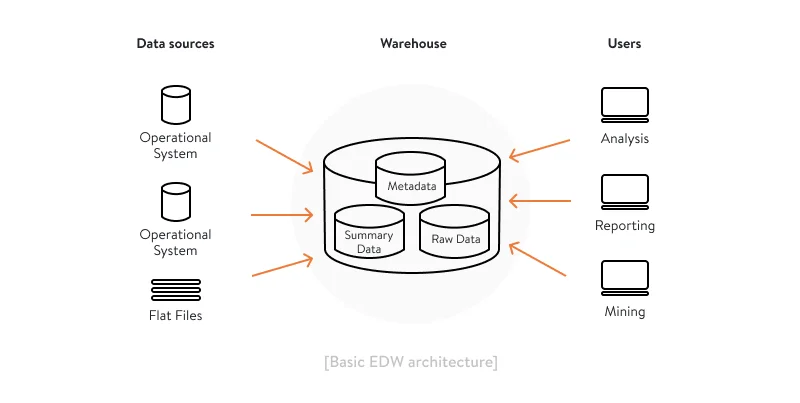
Basic architecture
This example of an enterprise data warehouse architecture roughly corresponds to Inmon’s day one of a data warehouse implementation. It’s hardly possible, however, to unleash full enterprise data warehousing potential with a basic architecture only. At this stage, you simply configure the data flow from your corporate data sources to a new entity — enterprise data warehouse software.
Architecture with a staging area
This architecture already suggests setting up a data warehouse with an ETL (extract, transform, load) logic with the help of inserting a staging area. At this point in your EDW implementation, you start loading business data from your systems of record into the data warehouse through a staging area that cleans and transforms data to fit it into the necessary place in the data warehouse and in the necessary format.
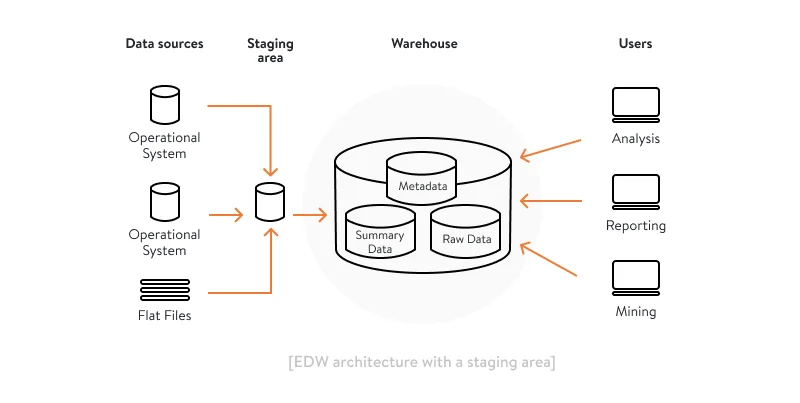
Architecture with a staging area and data marts
To simplify data search and allow different departments to simultaneously access only those datasets they need for their business purposes, you can also build data marts on top of your data warehouse.

The end result is a layered enterprise data warehouse architecture that fully integrates into your enterprise data management framework:

- The ingestion layer is a staging area that prepare data before loading it into the data warehouse.
- The storage layer consists of the data warehouse itself and data marts, which store data and keep it in the right places and formats so it’s ready for analytical purposes.
- The presentation layer allows for retrieving the necessary data using all kinds of business intelligence tools and web services to visualize, analyze, and view it as insights rather than mere tables and columns.
Best practices for EDW implementation and support
- Involve business users from the get-go. It’s not only your software systems, but also employees who hold critical business information. Performing one-on-one interviews with different business stakeholders can help you gain a better understanding of important data sources, the most critical business issues, and failing customer interactions that cost you money.
- Work with an expert data team. Throughout this article, we often mention that you should work with data professionals when considering data warehouse implementation, especially at the enterprise scale. EDW implementation touches architecture, governance, ETL pipelines, and analytics workflows. A skilled data team (internal or external) can design scalable systems, avoid performance bottlenecks, and choose the right tools from the start, saving you money and time later on.
- Plan for future scalability and integration. Your EDW should be able to handle growth in both data volumes and business complexity. Choose architecture and tools that can evolve with you, and ensure compatibility with your broader data ecosystem (BI tools, AI/ML platforms, etc.).
- Train users and transfer knowledge. Organize practical training sessions for analysts, managers, and decision-makers. Document processes, create easy-to-follow guides, and designate internal champions who can support others.
- Appoint a CDO/CAO. Hiring a Chief Data or Analytics Officer is a great step, but make sure they’re embedded in strategy, not isolated in IT. Give them the authority and budget to influence cross-functional data decisions.
Ready to implement your enterprise data warehouse?
Let’s switch from discussion and considerations to real actions. If developing and implementing an EDW has been on your mind and business agenda for a while, it’s time to get started. You can develop and implement an EDW steadily and gradually. And we can be by your side during the whole process. Remember those steps to create a data warehouse? You can take all of them alongside our domain experts and technical specialists. This way, we’ll ensure a custom approach to meeting your current data management issues.
FAQ
What business problems can an enterprise data warehouse strategy solve?
An EDW helps eliminate data silos, reduce reporting delays, and improve decision-making by storing all of your critical data in a centralized repository. It allows cross-functional team collaboration, as your employees can easily access accurate insights and make data-driven decisions.
Is creating a data warehouse suitable for mid-size businesses?
Definitely, especially if you’re scaling fast or rely on data to make strategic decisions. A well-designed EDW helps mid-size companies stay agile, improve data accuracy, integrate data from disparate sources and support advanced analytics without the chaos of scattered spreadsheets and systems.
How long does it typically take to implement an EDW?
It depends on your goals, data complexity, and team. A basic EDW setup can take 3–4 months, while a full-scale implementation may take 6–12 months. Starting with a phased rollout is often the smartest way to deliver value early and scale gradually.
How secure is an enterprise data warehouse for storing sensitive data?
When implemented properly in the hosting environment that’s best suited for your business, an EDW is highly secure. With role-based access controls, encryption, monitoring tools, and compliance support (like HIPAA, GDPR, or ISO 27001), it can safely handle even the most sensitive enterprise data, whether on-premises or in the cloud.
Should we choose a cloud-based or on-premises EDW solution?
That depends on your budget, internal expertise, infrastructure setup, and data sensitivity. Cloud offers faster setup, easier scaling, and lower overhead. On-prem makes sense if you need full control, meet strict compliance standards, or already have a robust in-house infrastructure.
How do we maintain and scale an EDW over time?
Ongoing success depends on proactive monitoring, regular data quality checks, and adapting your architecture as business needs evolve. Whether cloud or on-prem, a good EDW should support modular scaling, adding new data sources, users, or analytics tools as you grow.
About the author