Are you sure you’re collecting all the data your business requires? We bet you are. But most likely, this data is scattered among various enterprise systems and may even be siloed, so you miss it when executing your data analytics. To analyze your organizational data and turn it into valuable insights, you should create and maintain a central data repository.
However, implementing a data repository is transformative not only in terms of data management but also in terms of business processes. Therefore, it’s crucial to make a considered choice from a whole list of data repositories available on the market. In this article, we’ll provide you with a comparison of data repositories to help you choose the most suitable one — or maybe more than one. Let’s begin with the challenges you might be facing right now with day-to-day data management.
Read also: Our expertise in creating custom data science solutions
Challenges to solve with a data repository
The more digitally advanced our world becomes, the more data we generate. A digital transformation process won’t fully unveil its potential if an organization doesn’t properly analyze the data each digital solution collects. A data repository enables deep data analysis and helps organizations extract valuable insights from terabytes of diverse datasets.
Data management is associated with many challenges. But a fitting data repository can come to the rescue. Below are typical challenges data repositories can solve.
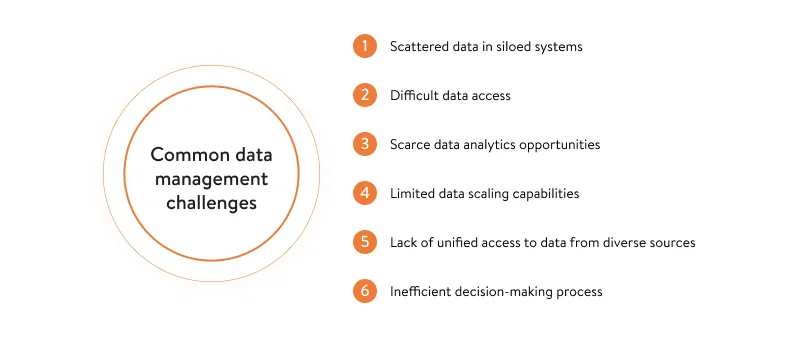
- Scattered data in siloed systems. Business data scattered across diverse databases becomes a serious bottleneck on the way to efficient data management and data analysis. Data repository platforms serve as a single source of truth for your organization and help to prevent meaningful data from being trapped in siloed legacy systems.
- Difficult data access. The more points of access to data, the harder it gets and the longer it takes to find the right data. A data repository allows your analytics team to easily access through a single entry point any datasets they need to spot dependencies between data elements. Plus, a central data repository makes it easier to manage access permissions.
- Scarce data analytics opportunities. Employing data science services can uncover untapped potential in your datasets, helping your team generate more actionable insights tailored to evolving business needs. If you’ve been using a certain data analytics approach for years, you may come to a place where your data reports are no longer relevant to your current business needs. Building a data repository allows you to easily analyze your business data from different perspectives. Without a data repository, you’ll have to invest much more time in building separate pipelines for extracting data directly from your corporate systems.
- Limited data scaling capabilities. When a business grows, the volume of data grows as well. It gets harder to even store this ever-growing flow of data, not to mention catalog and analyze it. You can implement a data repository that can scale along with your growing volume of data to ensure that you’ll never run out of capacity to store and analyze your business data.
- Lack of unified access to data from diverse sources. Today, anything can be a data source: news websites, Twitter posts, Instagram reactions, IoT and telematics devices (IoT solutions for healthcare). With modern data repository solutions such as those provided by AWS and Microsoft Azure, it is possible to integrate data from external sources (like those described above) and internal sources (your ERP, CRM, etc.). This allows you to look at your business from different perspectives without much effort.
- Inefficient decision-making process. Ideally, each business decision should be backed by reliable facts. Data-driven business environments can allow executives to be more confident, be more ambitious, and make less risky decisions. Consequently, the more data you gather and analyze, the better the foundation you’ll have to drive more efficient business results.
Now that we’ve looked at the data repositories definition in general, let’s discuss each type of data repository separately to spot their differences, similarities, and use cases. All of the best data repositories have one common purpose: to open up more data analysis opportunities for your organization.
Read also: How we implemented a real-time election data processing solution
Data lake vs data warehouse vs data mart
In this section, we focus on three major types of data repositories.
Let’s begin with a data lake. We’ll clearly define what a data lake is, explore different data repository models, and tell you how to build a data lake.
Read also: How we implemented a data lake for a manufacturing company
1. Data lake
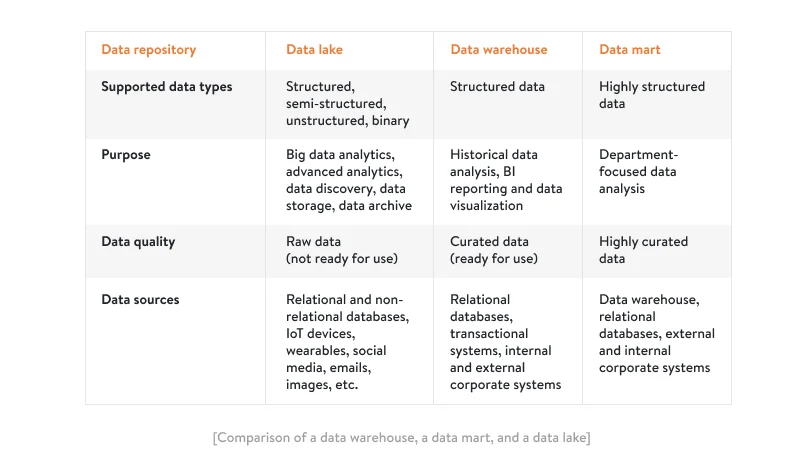
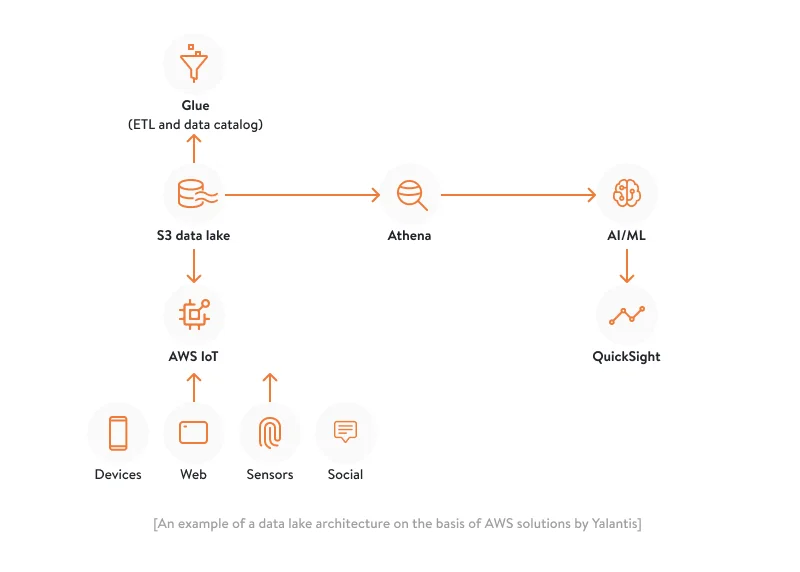
A data lake is a central repository database that can store any kind of raw data including structured, semi-structured, unstructured, and binary coming from different sources. These sources could be social media, websites, IoT devices, or RFID tags, all comprising the big data flow. Below is an architectural diagram for a project in which we implemented a data lake for a manufacturing company. To successfully deploy a data repository for this company, we built an elaborate data lake architecture with AWS data lake technology. Our big data solutions helped streamline the management and processing of this data, enabling better insights and decision-making. You can also check out a big data analytics solution we’ve developed for a 3PL company.
Why a data lake?
- Advanced analytics. Thanks to the versatile nature of the big data that data lakes can store, data scientists and data lake architects can make use of machine learning (ML) and artificial intelligence (AI) algorithms to generate deep analytical insights.
- Research and discovery. Raw data in data lakes can be the perfect grounds for conducting all kinds of analytical research that wouldn’t be possible with the help of only a traditional data warehouse.
Example:
Medical equipment manufacturer and distributor DRG Diagnostics shifted its datasets to a cloud data lake to derive actionable insights from large sets of healthcare data. The results of this shift were astonishing. Within the first three months of adoption, the company managed to:
- become 1.5 times more productive
- support five times more users
- onboard more than 100 terabytes of data
Data lake vs data warehouse:
- A data lake stores raw data that isn’t ready for data analysis straight away, whereas a data warehouse stores structured data (curated data) that is ready for business intelligence reporting and data visualization.
- Another difference between a data lake and a data warehouse is that a data lake can receive real-time data while a data warehouse stores historical data.
- Data from a data lake is suitable for advanced analytics and building AI/ML algorithms, whereas data in a data warehouse is best for business intelligence.
With the right bi solution delivery, companies can leverage data from a data warehouse to create comprehensive reports and visualizations, empowering decision-makers to take informed actions.

Data lake vs data mart:
- A data lake is much larger than a data mart.
- It’s easier to maintain and manage a data mart compared to a large data lake.
- Thanks to the field-specific nature of a data mart, data analysts can quickly access data in a data mart to facilitate decisions at the departmental level. Even though data in a data lake is cataloged, it may take longer to extract the necessary information compared to a data mart.
- A data lake provides much more diverse datasets that give data scientists more flexibility in data modeling (data modelling examples), while a data mart helps in generating rather straightforward insights.
In the next section, we discuss data warehousing and answer a common question: What does data warehousing allow organizations to achieve?
Read also: How we aggregated customer financial data for a platform for financial advisory operations
2. Data warehouse
What is a data warehouse repository? It’s a data repository that stores structured historical data. With the help of an ETL (extract, transform, load) engine, data is transferred to the data warehouse from different data sources such as transactional databases, data banks, the web, log files, and data lakes.

There are two major architectural approaches to build a data warehouse: Inmon’s and Kimball’s.
- Inmon’s architectural approach is also called the corporate information factory. This approach suggests developing an enterprise-wide data warehouse that stores all the enterprise’s structured data.
- Kimball’s approach is named the dimensional model data warehouse. This approach allows for quick reporting without the necessity of capturing all the data to form a single source of truth within an enterprise.
The choice of architectural approach largely depends on the business’s needs. But Inmon’s data management system is more common.
Why a data warehouse?
- BI data visualization. A data warehouse is the most suitable data source for BI tools. A well-structured data warehouse enables quick data querying and, thus, is good for building detailed BI reports and dashboards on a daily basis.
- Online analytical processing (OLAP). This software allows data analysts to simultaneously extract insights from data in different databases. Since a data warehouse stores clean and structured data from the entire enterprise, that data can be easily loaded into an OLAP server for elaborate analysis.
Example:
Executives at Texas Children’s Hospital have received $4.5 million of direct benefit from their four enterprise data warehouse projects. Now, all meaningful data the hospital gathers is collected, structured, and analyzed to produce operational insights instead of being trapped in separate systems like electronic health record (EHR) systems.
Next, we will consider the definition of a data mart and how to create a data mart. At the end of the following section, we’ll sum up the key difference between a data warehouse and a data mart.
Read also: How to create an enterprise data warehouse from scratch
3. Data mart
Data marts are a subset of data warehouses. A data mart also contains structured data but is only relevant for a certain department, such as marketing or finance. A data mart is a much smaller data repository compared to a data lake and a data warehouse. Plus, there can be several data marts in an organization, each responsible for a certain division within the organization.
According to Kimball, there are three main types of data mart development:
- Independent. This type assumes that data marts are built as separate small data repositories for each corporate department and don’t depend on data in the data warehouse.
- Dependent. These data marts are dependent on the central data warehouse. All the structured data in the enterprise first comes to the data warehouse and only after that does each data mart receive its subject-specific data.
- Hybrid. This type of data mart architecture supposes that an organization has both dependent and independent data marts. The hybrid deployment approach is best suited for handling sensitive data in independent data marts and less sensitive data in dependent data marts. There must be a truly good reason for developing a hybrid data mart, as it’s much easier to build a few dependent data marts than several independent ones.
Why a data mart?
- Secure data access within an organization. As a result of building data marts, each department will be able to access only their particular data mart and won’t need access to the central data warehouse.
- Department-focused data analytics. Thanks to the well-organized structure of department data in data marts, business analysts can quickly retrieve only necessary data for analysis without needing to query it through the whole data warehouse.
Example:
The McDonald’s data analysis team found it difficult to use a data warehouse only for sales data analysis to make better predictions on the outcomes of loyalty programs and menu changes. Implementing a data mart on the AWS platform helped data analysts make more precise analyses, such as comparing sales across different times of the day. A data mart collects loyalty data as well as data from point of sale (POS) systems and store operating software (SOS), simplifying the sales data search for McDonald’s business analysts.
Data warehouse vs data mart:
- According to Inmon’s data architecture approach, the primary data source for a data mart is a data warehouse, while a data warehouse receives structured data from all relational databases in the organization.
- A data warehouse is a multi-purpose data repository, as it stores enterprise-wide data. A data mart is a subject or department-oriented data repository and stores only data related to a certain subject or department.
- A data mart is a significantly smaller data repository than a data warehouse.
By now, you understand the main idea of all three data repositories as well as their core differences. This should allow you to define the best solution for your enterprise. Let’s talk about possible ways of implementing a data repository in your organization.
Read also: Our expertise in big data and analytics
On-premises or cloud-based data repository?
In this section, we’ll have a look at two possible ways to deploy a data repository — on-premises and in the cloud. Each implementation scenario has its advantages, disadvantages, and preferable use cases.
On-premises implementation
Judging by the growing demand for cloud computing services, it may seem that on-premises infrastructure has lost its influence. But that’s not true. On-premises implementations are still relevant, as they offer the highest possible security and sometimes are required for compliance with laws, standards, and industry regulations. Let’s briefly cover specifics of this approach:
- Individual hardware and software setup. When establishing on-premises infrastructure, an organization needs to invest in data centers and servers as well as hire an IT team to maintain on-premises infrastructure. And depending on the storage capacity of your data repository, you’ll need a different amount of storage space. Keep in mind that a data lake needs much more space than a data mart, as data lakes store large amounts of raw data in all formats.
- High data security and governance. Implementing an on-premises data repository can guarantee your data is highly secured since only your organization owns and governs the servers on which your data is stored. This approach is especially suitable for storing sensitive data like personal health information (PHI) or credit card details.
If an on-premises implementation can’t completely cover your needs, luckily, you don’t have to choose only an on-premises or only a cloud implementation. Certain data repositories simply work better on cloud services — like a data lake, for instance — while others like a data mart can be perfectly installed on-premises. Let’s take a closer look at cloud computing. Probably, you can consider deploying some of your data repositories (or all of them) in the cloud.
Cloud implementation
Cloud computing is popular primarily thanks to its cost-effectiveness compared to on-premises infrastructure. However, Dave Raffo, a Senior Analyst at Evaluator Group, says that the cloud isn’t always cheaper, especially if you deal with big data. Its core benefit is a much simpler buying process and simpler maintenance as well as the potential for on-demand scaling.
There are three types of cloud services, and each has its own peculiarities.
- A private cloud offers cloud services for one organization only. Often, private clouds are confused with on-premises implementations, as they’re alike in terms of their high security and data governance capabilities (data governance models). However, a private cloud is more expensive and less scalable compared to a public cloud.
- A public cloud is a solution completely governed by third-party providers like data lake vendors (AWS, Microsoft Azure, etc.) and doesn’t require any investments in IT teams to maintain it. It’s the easiest solution to scale compared to on-premises servers and private clouds, and it can handle high software workloads.
- A hybrid cloud is a solution that combines both private and public cloud options. In such an environment, data can be moved between multiple clouds. With a hybrid cloud, an organization can keep more sensitive information in a private cloud, whereas large datasets with fewer security requirements can be stored in the public cloud.
As you can see, it’s definitely possible to mix your own cocktail of data storage possibilities, as you don’t have to stop on one type of infrastructure only. Take a look at the cloud migration checklist on our blog to be confident about diving into cloud migration. To learn more about hybrid data handling possibilities for the healthcare industry, check out our cloud-based medical imaging system for a US hospital network.
As your company grows, it’s recommended by most cloud services vendors to switch to multiple cloud environments, where you can use different cloud types. To avoid getting confused with all the cloud options out there, let our cloud and DevOps center of excellence help you choose the most appropriate cloud technologies for your current business model.
Use cases for implementing a data repository across industries
The essence of the data repositories mentioned above is practically the same for all industries. In fact, any industry will benefit from enhanced data analytics capabilities as a result of storing data in data repositories. However, there are certain specifics depending on the types of stored data and data protection requirements. That’s why it might be wise to hire a domain-focused IT team to develop and deploy a data repository for your organization.
In this section, we discuss three industries: supply chain, FinTech, and healthcare. Our company has worked closely with clients in each of these industries.

Use cases for the supply chain industry
Proper management of supply chain data is essential to meet volatile customer demands and ensure an uninterrupted workflow at many organizations that depend on the timely supply of materials. Below are use cases worth considering when implementing a data repository for a supply chain company:
- Supply and demand forecasting. Awareness of supply and demand fluctuations can allow you to significantly optimize supply chain operations. Implementing a data lake can be your gateway to advanced analytics, which allows for accurate supply and demand forecasting. We discuss this in greater detail in our blog post on advanced supply chain analytics. Advanced analytics allows for analyzing any type of data like PDF documents, emails, videos, and images with the help of AI/ML algorithms and other advanced technologies.
- Enhanced reporting across departments. The supply chain often involves many parties like suppliers, manufacturers, and carriers. Thanks to a data mart implementation, each party can have easy access to data relevant for their particular department and, as a consequence, can better capture their overall performance through reporting.
Use cases for the FinTech industry
Like all other industries, the financial services industry derives lots of value from data analytics. Implementing a single source of truth in financial organizations can help deliver insights from customer data to improve the quality of delivered services.
However, the sensitive nature of financial data should also be taken into consideration when implementing a data repository. Such data should be stored safely; but it’s also necessary to ensure that only authorized users can access, retrieve, and analyze it.
Use cases for implementing a data repository in the FinTech domain could be as follows:
- Seamless reporting for regulatory assessments. Since financial companies are usually subject to compliance assessments, it’s beneficial for such companies to have continuous access to company data. In this case, an all-in-one data repository can give data analysts the chance to quickly generate necessary financial reports.
- Automated and AI-powered decision-making. Storing customer data in unified data repositories allows financial data analysts to make use of ML and AI technologies. These technologies can automate and, therefore, simplify decision-making at the financial institution. For instance, a bank can automate a credit approval process by quickly analyzing all structured and unstructured customer data collected in data warehouses and data lakes.
Read also: Secure application development from planning to production
Use cases for the healthcare industry
Healthcare organizations also have to comply with lots of data protection requirements like HIPAA in the US, the GDPR in Europe, and many more healthcare laws and regulations in other countries. That’s because healthcare data is often sensitive and requires additional security measures. Unfortunately, data breaches are most frequent in the healthcare industry — and at the same time, the most impactful. Thus, data repositories should be built considering all necessary security measures.
If an organization is considering migrating its services and documentation to the cloud, a cloud provider must ensure compliance with necessary requirements. For example, AWS enables cloud services to comply with the most widespread healthcare laws like HIPAA as well as with financial standards such as PCI DSS.
Common use cases for implementing a data repository in the healthcare industry include the following:
- Telemedicine. Data repositories are a must for digital healthcare services. A patient’s health and life depend on the accuracy of a clinician’s diagnosis. The possibility to gather and analyze data from wearables and IoT devices like Bluetooth EKG monitors can help clinicians make more accurate diagnoses. You can read more on this topic in our detailed case study about a telemedicine and remote patient monitoring project.
- Clinical research. Data-intensive clinical research drives forward the entire healthcare industry. Big data analytics allows scientists to dig deep into clinical trials, achieving breakthroughs and saving people’s lives. For instance, thanks to cloud computing and impressive storage infrastructure, Moderna scientists were able to deliver the first batch of COVID-19 vaccines just 42 days after the start of the pandemics. The company has also recently started human clinical trials of an HIV vaccine.
The supply chain, FinTech, and healthcare domains can benefit in different ways from implementing data repositories. But one thing all of them have in common is that with access to large datasets, they can deliver their services faster, generating more revenue and more satisfied customers. Plus, the right data repository can be a great basis for developing a seamless digital end-to-end solution within your organization. Let’s find out in the next section how you can implement a data repository with as few issues as possible.
What to consider to ensure a smooth data repository implementation
To build a data repository, you need a team of IT professionals preferably with experience in your domain and with real-world expertise. You can choose to hire in-house or decide on outsourcing. Your choice will depend on your needs and expectations. Make time to read our article where we confront common myths about outsourcing so you can be sure you’re making the right (and unbiased) decision.
In this article, we want to share with you a few tips on how to make a seamless transition to a data repository.
- Start with a proof of concept (PoC). Many data repository providers like AWS offer the possibility to deploy a data repository as a PoC first. You can consider this option to make sure that investment in a data repository is going to be beneficial for your organization.
- Ensure stakeholders’ buy-in and sponsorship. Once you deploy a PoC and start generating the first results, you can readily present this new solution to your company’s stakeholders and sponsors. Even if your organization is prone to conventional decision-making based on managers’ experience, data-driven reports can be compelling enough to prove the viability of a full-fledged data repository implementation.
- Begin with a data warehouse or a data lake, then consider data marts. Data warehouses and data lakes are much bigger data repositories than data marts. Therefore, it’s wise to deploy one of them first before considering a data mart. With a data warehouse or a data lake, you’ll quickly see the results and assess the importance of deploying a data repository for your organization.
- Remember that data scaling capabilities are essential. Simply accept that with time, data volumes are only going to grow. Thus, ensure that your data repository is capable of scaling easily. Scaling is a convincing advantage of cloud services.
These four simple tips can help you safely transition to a single source of truth. If you opt for the services of a professional IT team to deploy your data repository, you can count on an exhaustive consulting session before the actual work begins. During this consultation, you can address with our team any lingering doubts and anxieties that restrain you from improving your usual data management practices. Get in touch with our experts available for consultation.
Want to boost data analytics at your company?
We can implement the right data repository for you.
FAQ
What are common types of data repositories?
There are such common types of data repositories as data warehouse, data lake, data mart, metadata repository, and data cube.
What is a data management system?
A data management system is built for gathering and analyzing a big amount of data that an organization collects. Such systems usually incorporate data management tools that are created by the database or third-party providers. These systems allow IT specialists and database administrators to solve issues in the database system or infrastructure, change the database design, and more.
Why should your organization use data repository platforms?
Data repository platforms provide your organization with a single source of truth and ensure that valuable data isn’t stuck in siloed legacy systems.
About the author