The way your app approaches data management can make or break the user experience. Imagine having an app with a great UI and clean code, but that takes ages to fetch data, or, worse, can’t keep that data safe. This is why choosing the right database management system (DBMS) is important.
Your database is responsible for your app’s performance, making sure everything runs smoothly and securely. And while choosing from the over 300 databases on the market can be difficult, we’re happy to help you with this task.
Our team has already done the legwork, sifting through the options to find the gems that will suit your project best. In this guide, we explore how to choose a database for your project and which database to use for the best business results, breaking down the when, why, and how of the most popular database solutions.
Quick instructions on how to navigate this article:
- If you’re new to the database selection, we recommend reading the entire article in order. Each section builds on the previous one to help you eventually reach the final decision, or at least realize that you have additional questions, which our team will be happy to answer.
- If you’re considering which database to choose, feel free to jump directly to the detailed breakdown, describing nine popular database options. Don’t miss the comparison table at the end, it summarizes all the key insights.
6 steps and questions to pick a database for your project
Before we dive into the detailed database comparison, discover what criteria impact the choice of the database. We present these criteria in the form of steps, as each criterion also requires a certain action from your business. Combined with a relevant question, each step on how to choose a database helps to set the right mindset with which you should be reading this article, which is keeping in mind your unique business needs.

Step 1. User load
Question: How many people will use our application simultaneously?
When selecting a database, the expected number of people who will use your application is essential. For instance, databases such as SQLite might be a great fit for prototyping, but they lack the performance capacity to maintain lots of users in production-ready solutions.
Step 2. Security vs. performance
Question: Do we prioritize data security or application performance?
As it stores all user data, a database should be well-protected. ACID (atomicity, consistency, isolation, and durability) -compliant relational databases are more secure than non-relational databases that work on the principle of the BASE (basically available, soft state, and eventually consistent) approach and trade consistency and security for performance and scalability.
Step 3. Unique business needs aligned with data types
Question: What are our other critical non-functional and business requirements?
Apart from performance and scalability, consider what else you expect from your software solution, and take into account all of the non-functional and business requirements when deciding which database you should use. For instance, if you expect your software to fetch and display data from other systems, such as medical imaging software, then your database system should also support unstructured data to display medical images in a consistent format to all software users.
SQL databases are perfectly suited for storing and processing structured data, while NoSQL databases are the best solution for working with unstructured or semi-structured data. If you will manage both structured and unstructured data, you can opt for mixing SQL and NoSQL databases
Step 4. Scalability
Question: Do we plan to scale our database in the future?
As your web product grows, its database should grow as well. Your choice of database may be affected by the type of scaling you prefer, whether horizontal or vertical. Non-relational databases with their key–value stores are optimized for horizontal scaling, while a relational data model is optimized for vertical scaling.
Step 5. Analytics and AI readiness
Question: Do we want to analyze our data or implement any advanced technologies in our application, like machine learning and artificial intelligence (AI)?
Your choice of database for a modern application also depends on the type of analytics you’ll want to perform. For instance, if you need a database that would be best to store large amounts of structured data for further analysis, you should also set up a data warehouse. If you need to store and analyze big data or large amounts of unstructured data, on the other hand, you should choose a data lake. Learn how we helped a 3PL company aggregate and analyze big data from multiple sources with the help of a data lake.
Learn how we helped a 3PL company aggregate and analyze big data from multiple sources with the help of a data lake
Explore the case studyStep 6. Integrations
Question: Do we need to integrate data and our database with other solutions such as business intelligence tools?
Important note for choosing a DBMS: make sure that your database management system can be integrated with other tools and services within your project. In most cases, poor integration with other solutions can stall development.
For instance, ArangoDB has excellent performance, but libraries for this DBMS are immature and lack support. Using ArangoDB in combination with other tools may be risky, so the developer community suggests avoiding ArangoDB for complex projects.
In the next sections, we compare general database types and then move on to specific examples with potential use cases in different industries.
Struggling to unlock the full potential of your data?
Yalantis’ data analytics expertise can help you transform your raw data into valuable insights for informed decision-making
Types of databases: SQL vs NoSQL
When it comes to choosing the best database solution, one of the biggest challenges is picking between an SQL (relational) and NoSQL (non-relational) complex data structures. While both have good performance, there are key differences you should keep in mind.
| Name |
SQL Databases |
NoSQL Databases |
|
Type |
Relational (table-based) |
Non-relational (key-value, document, column, graph) |
|
Structure |
Predefined schema with rows (tuples) and columns (attributes) |
Schema-less or dynamic schemas, depending on subtype |
|
Query language |
SQL (standardized, widely supported) |
Varies by DB type (custom APIs or query languages like MongoDB Query Language) |
|
Scalability |
Vertical (scaling up requires more powerful servers) |
Horizontal (scale out by adding multiple servers) |
|
Data integrity (ACID, BASE) |
Full ACID compliance: atomicity, consistency, isolation, durability |
Limited ACID properties; BASE compliance (basically available, soft state, eventually consistent) |
|
Performance |
High for structured data and transactional operations |
High for large volumes of semi-structured or unstructured data |
|
Security |
Mature access control mechanisms, strong user permission models |
Varies; often less mature than SQL but improving |
|
Best use cases |
Financial systems, healthcare apps, ERP systems, CRM platforms |
Content management, real-time analytics, IoT, social media, caching, large-scale web apps |
|
Disadvantages |
– Poor performance with unstructured data – Not optimized for distributed systems – High hardware cost for scaling |
– Limited complex querying – Learning curve for different query languages |
SQL databases
A relational database is a set of tables that have predefined relationships between them. It’s the most used type of database management system. To maintain and query a relational database, the database management system uses Structured Query Language (SQL), a common user application that provides an easy programming interface for database interactions.
Relational databases consist of rows (tuples) and columns (attributes). Tuples in a table share the same attributes.
Advantages of SQL databases
- Great fit for structured data. A relational database is ideal for storing structured data (zip codes, credit card numbers, dates, ID numbers). The best SQL databases are PostgreSQL and MySQL.
- Security. Modern relational databases support access permissions, which define who is allowed to read and edit the data. A database administrator can grant particular user privileges to access, insert, or delete data. This gives no chance for third parties to compromise business data.
- Compliance with ACID (atomicity, consistency, isolation, and durability) properties. To better understand what this means, let’s assume that two buyers are trying to simultaneously purchase a clothing item of the same size. ACID compliance ensures that these transactions won’t overlap with each other.
- Atomicity means that each transaction (a sequence of one or more SQL operations) is treated as a unit. When a user purchases an item, money is withdrawn from the user’s account and deposited into the merchant’s account. Atomicity ensures that if the deposit transaction fails, the withdrawal operation won’t take place.
- Consistency means that only valid data that follows all rules can be written in the database. If input data is invalid, the database returns to its state before the transaction. This ensures that illegal transactions can’t corrupt the database.
- Isolation means that unfinished transactions remain isolated. It ensures that all transactions are processed securely and independently.
- Durability means that the data is saved by the system even if the transaction fails. Thanks to durability, data won’t be lost even if the system crashes.

ACID compliance is beneficial for apps handling sensitive financial, healthcare, and personal data, since it automatically provides safety and privacy to users.
Disadvantages of relational databases
- Relational databases don’t work efficiently with semi-structured or unstructured data, so they aren’t a good fit for large loads and IoT analytics.
- When the data structure becomes complex, it becomes harder to share information from one large data-driven software solution to another. At big institutions, relational databases often grow independently in separate divisions.
- Relational databases are run only on one server, which means that if you want your DBMS to cope with a larger amount of data, you need to invest in costly physical equipment.
These drawbacks have forced developers to search for alternatives to relational databases. As a result, NoSQL and NewSQL databases have emerged.
Learn how Yalantis built a real-time web-based election database analytics platform using Aurora MySQL database
Explore the case studyNoSQL databases
NoSQL (“not only SQL”) databases represent a broad class of database management systems known for their non-relational nature. These databases serve as an alternative to relational databases. They can store and process unstructured data (photos or music from social media, IoT sensor data, etc.), offering developers greater flexibility and scalability.
Advantages of NoSQL databases
- Scalability. NoSQL databases excel at horizontal scalability, making it easy to handle massive amounts of data and accommodate growing workloads by adding more servers to a cluster.
- Flexibility. NoSQL databases allow developers to store and manipulate data with varying structures without the constraints of a fixed schema. This flexibility is ideal for projects where data schemas evolve over time, as it allows for agile development and seamless data integration.
- High fault tolerance. NoSQL databases are designed for fault tolerance and can continue to operate even if some nodes or servers fail. This makes them well-suited for applications requiring high availability and reliability, such as IoT systems, e-commerce platforms, and content management systems.
Disadvantages of NoSQL databases
- Limited ACID transactions. NoSQL databases often prioritize performance and partition tolerance over strict consistency (ACID properties). This can lead to situations where data may not be immediately consistent across all nodes, which may not be suitable for applications that require strict data integrity.
- Lack of a standardized query language. Unlike relational databases that use SQL as a common query language, each NoSQL database may have its own unique query language or API. This can create a learning curve for developers and limit portability between different NoSQL systems.
- Limited support for complex queries. NoSQL databases may struggle with complex queries involving multiple data relationships, as they typically lack the robust query optimization capabilities of SQL databases. This can be a drawback for applications heavily reliant on complex data analytics services and reporting.
Types of NoSQL databases
Depending on the way NoSQL databases organize and store data, they fall into four main groups: key–value stores, document stores, column stores, and graph stores. Let’s discuss how all these structure types impact the performance of database solutions and find out where they can be used.
- Key–value stores
This is the simplest type of NoSQL database, which can store only key–value pairs and offers basic functionality for retrieving the value associated with a key. A key–value store is a great option if you want to quickly find information with a key. Amazon DynamoDB and Redis are the brightest examples of key–value stores.
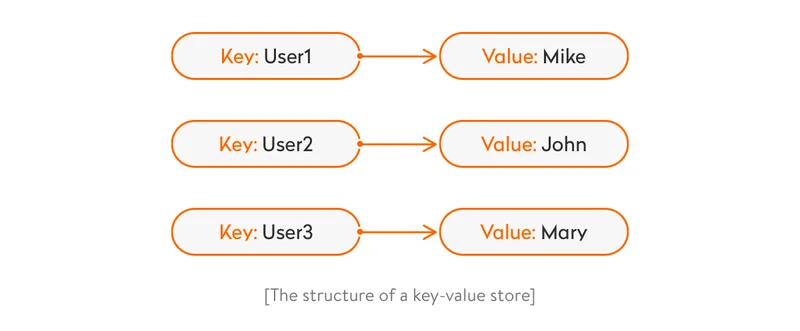
The simple structure of DynamoDB and Redis makes them the best scalable databases. With no connection between values and no construction schemes required, the number of values is limited only by computing power.
Key–value stores are used by hosting providers like ScaleGrid, Compose, and Redis Labs. Often, developers use key–value stores to cache data. These stores are also a good option for storing blog comments, product reviews, user profiles, and settings.
This type of database is optimized for horizontal scaling, which means you need to add more machines to store more data. This is less costly than scaling relational databases but may lead to high utility costs for cooling and electricity.
But the simplicity of key-value stores can also be a disadvantage. With a key–value store, it’s hard or even impossible to perform the majority of operations available in other types of databases. While searching by keys is really fast, it can take much longer to search by values.
In most cases, key–value stores are used in combination with a database of another type. In the Healthfully and KPMG apps we developed, we used the Redis key–value store in combination with the PostgreSQL relational database management system.
- Document stores
Document-oriented databases store all information related to a given object in a single BSON, JSON, or XML file. Documents of the same type can be grouped into so-called collections or lists. These databases allow developers not to worry about multiple data types and strong relations.
A document-oriented database usually has a tree or forest database model. A tree structure means that a root node has one or more leaf nodes. A forest structure consists of several trees. These data structures help document stores perform a fast search. While this makes it difficult to manage complicated systems with numerous connections between elements, it lets developers create document collections by topic or type.
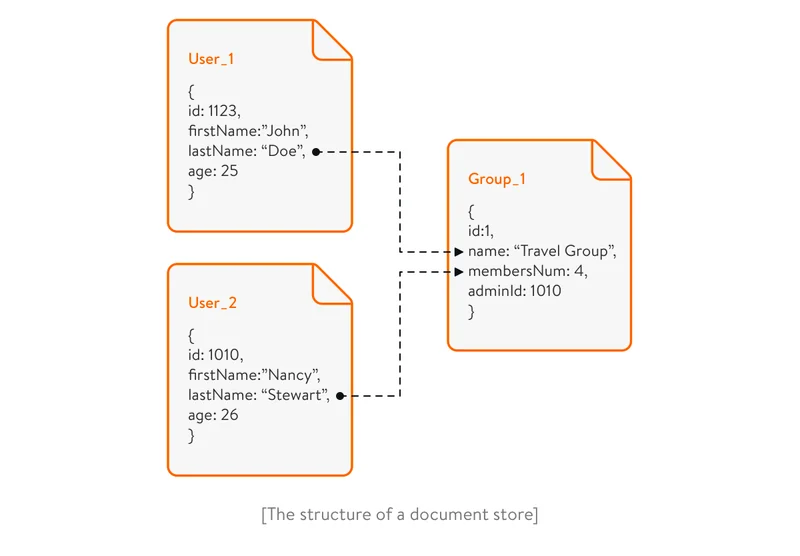
For instance, if you’re creating a music streaming app, you can use a document-oriented database to create a collection of songs in a certain genre so users can quickly find specific tracks.
To be flexible, document-oriented databases neglect ACID guarantees. MongoDB and Couchbase are great examples of document-oriented databases.
Thanks to their structure and flexibility, document-oriented databases are commonly used for content management, rapid prototyping, and data analysis.
- Column store
A columnar database is optimized for fast data retrieval of columns of data. Column-oriented databases store each column as a logical array of values. Databases of this type provide high scalability and can easily be duplicated.
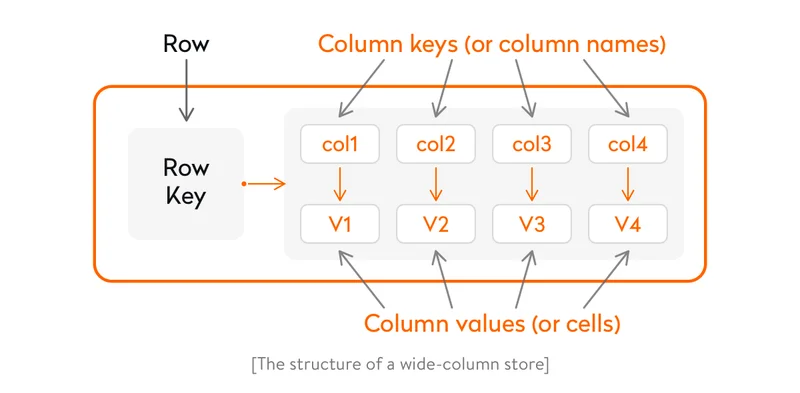
A column store deals well with both structured and unstructured data, making database exploration as simple as possible. Columnar databases process analytical operations fast but show bad results when handling transactions. Apache Cassandra and Scylla are among the most popular column stores.
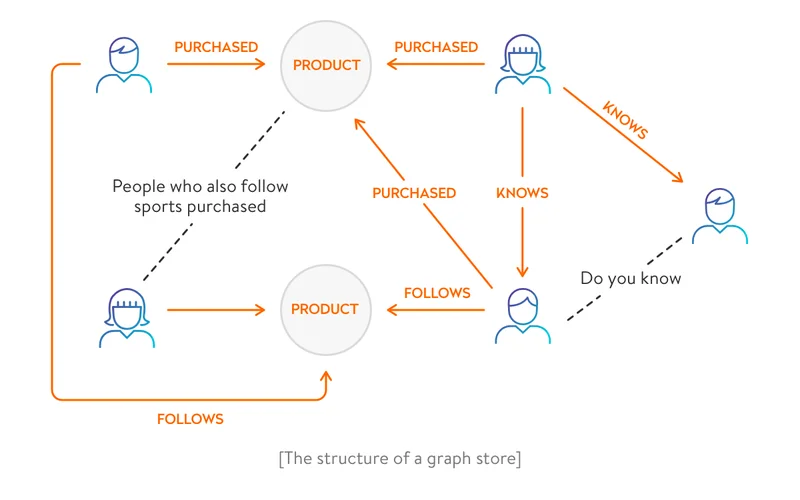
- Graph store
In a graph store, each entity, which is called a node, is an isolated document with free-form data. Nodes are connected by edges that specify their relationships.
This approach facilitates data visualization and graph analytics. Usually, graph databases are used to determine the relationships between different data points. Most graph databases provide features such as finding a node with the most connections and finding all connected nodes.
Graph databases are optimized for projects with graph data structures, such as social networks and the semantic web. Neo4J and Datastax Enterprise are the best examples of graph databases.
NewSQL – combining the best of SQL and NoSQL database solutions
Particular attention should be given to NewSQL, a class of relational databases that combines features of both SQL and NoSQL databases. Key characteristics:
- NewSQL databases are geared toward solving common problems of SQL databases related to traditional online transaction processing.
- From NoSQL, NewSQL inherited optimization for online transaction processing, scalability, flexibility, and a serverless architecture.
- Like relational databases, NewSQL database structures are ACID-compliant and consistent. They have the ability to scale, often on demand, without affecting application logic or violating the transaction model.
NewSQL was introduced only in 2011, and it still isn’t that popular. It has only partial access to the rich SQL tooling. Flexibility and a serverless architecture, combined with high security and availability without requiring a redundant system, increase the chances for NewSQL databases to become a next-gen solution for cloud technologies.
ClustrixDB, CockroachDB, NuoDB, MemSQL, and VoltDB are the most popular NewSQL databases.
In the next section, we discuss the distinction between online analytical processing (OLAP) and online transaction processing (OLTP), as your choice of database will depend on whether you’re planning to analyze your data.
Data processing approaches: OLAP vs. OLTP systems
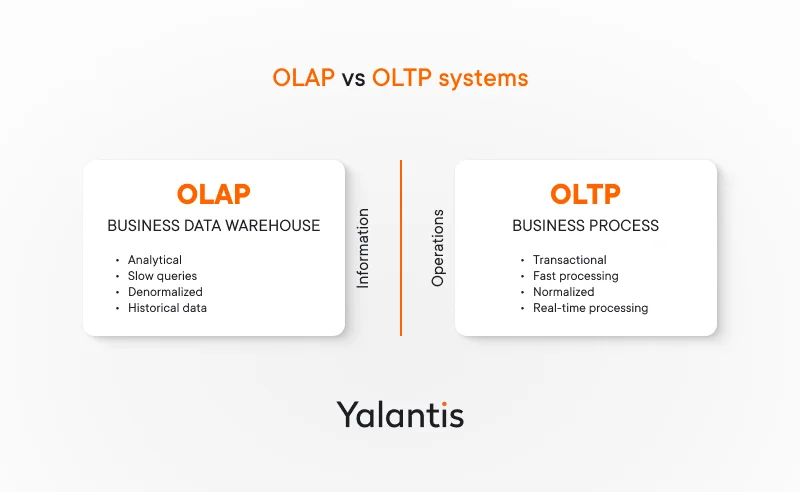
Your choice of data storage can also depend on the purpose of data processing. There are two common approaches to processing data: online analytical processing and online transaction processing.
- OLTP requires data from ACID-compliant relational databases. OLTP is responsible for running critical business operations in real time. For example, it is used for online banking and online shopping systems that capture multiple database transactions from multiple users.
- OLAP systems, in turn, focus on analyzing historical data and require the best analytics databases along with a large data storage system: a data warehouse, data mart, or data lake, depending on the type of data processed.
End users of OLTP systems are employees that, for instance, need to ensure that multiple customers can easily use company services simultaneously. OLAP systems are necessary for data scientists and data analysts to analyze data and generate insights, reports, and dashboards. Thus, if you’re planning to make use of data analytics in your project, you should opt for non-relational databases along with a data warehouse or a data lake on top of them.
It can also happen that you’ll need both OLTP and OLAP systems for your business. Such a combination is also possible, and it proves to be efficient for maximizing the potential of your data.
As you can see, there are multiple factors to consider when choosing the right database. In the next section, we look at the five most popular databases and explore their pros and cons.
Learn how building an enterprise data warehouse (EDW) can help you revamp your digital transformation journey
Read the article5 best database systems for your software solution
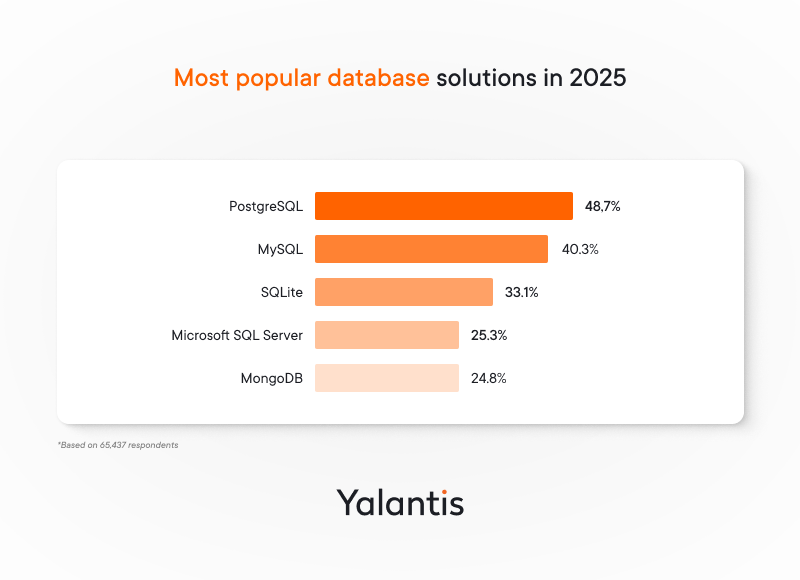
According to the 2024 Stack Overflow Developer Survey, four of the five most used examples of DBMS software belong to the SQL family:
- PostgreSQL
- MySQL
- SQLite
- Microsoft SQL Server
- MongoDB
Professional developers are more likely to use PostgreSQL (51%), and those learning to code are more likely to use MySQL (45%), based on 65,437 responses received.
Now, let’s discuss what makes these databases so popular and how you can integrate them into your project.
PostgreSQL
PostgreSQL is an object-relational database, which means that it’s similar to relational databases that represent data in the form of objects instead of columns and rows.
Pros:
- Offers a robust feature set including advanced indexing, full ACID compliance, and support for complex queries and foreign keys.
- Can be highly extensible and support custom data types and functions while closely adhering to SQL standards.
- Has a strong and active community that provides reliable updates and a wealth of learning resources.
Cons:
- Can be more resource-intensive compared to other databases, requiring more memory and processing power for optimal performance.
- Some of its features and settings are difficult to configure and manage, especially for beginners.
- Tends to have slower write performance compared to some other databases, which might be a limitation for write-heavy applications.
Companies that use PostgreSQL: Netflix, Uber, Instagram, Spotify, Instacart, and many more.
MySQL
Created in 1995 and managed by Oracle, MySQL is one of the most used database management solutions. This open-source database system has a huge user base and great support, and it works well with most libraries and frameworks. It’s free, but it offers additional functionality for an annual fee.
Pros:
- Great performance and scalability for a broad range of small and midsize applications, including web applications.
- Comprehensive set of features like stored procedures, triggers, views, and transactional support makes MySQL suitable for complex data management tasks.
- Large community constantly supports and improves database features and updates documentation.
Cons:
- Can have performance bottlenecks on large-scale databases and complex queries. If you’re planning to scale your product in the future, you might need additional support services, like MySQL Heatwave or MySQL NDB Cluster, which are expensive.
- Limited functionality for advanced analytics and reporting tools.
- Handling binary large objects (blobs), like multimedia files, can bring you up against system constraints.
Companies that use MySQL: Uber, Facebook, Tesla, YouTube, Netflix, Spotify, and Airbnb. Yalantis also uses this DBMS for data management and engineering.
Need to make sure that your data architecture is scalable and secure?
SQLite is an open-source, embedded SQL database engine. It doesn’t require a separate server process and allows access to the database using a nonstandard variant of the SQL query language.
Pros:
- SQLite requires minimal setup and configuration, making it easy to embed in applications.
- Since it’s self-contained, it has no dependencies, which contributes to its reliability and robustness.
- Needs no installation or administration, making it ideal for applications that require an uncomplicated database system.
Cons:
- Supports only serialized transactions, making it less suitable for environments with heavy write demands or multi-user access.
- Performance issues with large-scale data operations and high-volume transactions.
- Lacks built-in capabilities for networked or distributed database applications.
Companies that use SQLite: Adobe, Bosch, Dropbox, Firefox, Microsoft, and many more. This makes it an excellent choice for applications that require Siri integration in iOS, as it ensures smooth local data handling and responsiveness.
Microsoft SQL Server
Microsoft SQL Server is a relational database management system developed by Microsoft. It’s designed to handle a wide range of data processing applications in corporate IT environments, from small-scale single-machine applications to large internet-facing applications with many concurrent users.
Pros:
- Offers a wide array of built-in functionality including advanced analytics, robust security features, and comprehensive data management tools.
- Features seamless integration with other Microsoft products and services, enhancing productivity for businesses already using the Microsoft ecosystem.
- Known for high performance in transaction processing, business intelligence, and analytics, with strong scalability options.
Cons:
- Licensing and operating costs can be high, especially for larger organizations or those requiring advanced features.
- Can be demanding on system resources, particularly for larger or more complex deployments.
- Various data models, features, and configurations can require experienced database administrators for performance management.
Companies that use Microsoft SQL Server: Walmart, Reddit, Stack Overflow, Cisco, JPMorgan Chase, and many more.
MongoDB
MongoDB is one of the best databases for web apps. It’s also the database the Yalantis technology team most commonly uses in their projects.
MongoDB is a NoSQL database that stores all data in BSON (Binary JSON) documents. Thanks to this, it’s possible to perform data replication between web applications and servers in a human-readable format.
Pros:
- Allows for a dynamic, flexible data models and schema design, making it ideal for applications with evolving multiple data models.
- Easily scalable, supporting horizontal scaling through creating partitions (shards), and effective at managing large data volumes.
- Offers high performance for both read and write operations, particularly with unstructured data.
Cons:
- Can consume significant amounts of memory for data storage and indexing.
- Transaction management is still more complex compared to traditional relational databases, despite recent improvements.
- More complex and less intuitive aggregated data queries than in SQL databases potentially lead to a steeper learning curve.
Companies that use MongoDB: Bosch, Cisco, Forbes, Google, eBay, and many more.
4 alternative database solutions for your project
OracleDB
Oracle DB, an RDBMS developed in 1977, remains the most popular database management system and the most trusted solution on our list. It’s ranked first in the DB-Engines Ranking. Let’s look closely at the reasons for OracleDB’s popularity:
Pros:
- It’s backed by Oracle and, hence, is a reliable database. Developers point out that Oracle DB rarely goes down and receives regular updates.
- It scales well and is considered the best database for large datasets. Oracle database is currently bringing all its products and services to the cloud, resulting in more flexibility.
- It’s secure, scrupulously following modern security standards (including PCI compliance) and offering good encryption of sensitive data.
- It manages memory very efficiently and easily handles complex operations. Also, it effectively manages and organizes a variety of third-party tools.
- It outperforms other solutions in terms of speed of data access across the network.
Cons:
- Licensing and support costs for Oracle DB can be quite high, making it unaffordable for smaller organizations. A Processor License for the Standard Edition will cost you $17,500 per unit.
- Oracle has complicated documentation and lacks good guides. Even though customer support is helpful, some developers complain about long response times.
- Oracle DB can demand significant hardware and system resources, which may be a limitation for some deployments.
Use cases: enterprise applications, financial services, e-commerce
Redis
Redis, short for Remote Dictionary Server, is an open-source key–value store that’s often used as a caching layer to work with another data storage solution.
Pros:
- Stores data in-memory, allowing for extremely fast read and write operations, making it suitable for caching frequently accessed data.
- Supports various data structures like strings, lists, and sets, providing flexibility in data modeling.
- Offers built-in support for publish/subscribe messaging, enabling real-time communication between applications.
Cons:
- May not be suitable for use cases where data durability and persistence are critical, since it stores data in-memory.
- May not be a good choice for large datasets, as the amount of data Redis can handle is limited by the available RAM.
- Uses a single-threaded event loop, which can limit performance in certain scenarios, such as complex queries or blocking operations.
Use cases: caching, real-time data analysis, session storage, and retrieval
Elasticsearch
Elasticsearch is an open-source, distributed search and analytics engine built on top of Apache Lucene. It is designed to store, search, and analyze large volumes of data quickly and in real time.
Pros:
- Excels at full-text search, making it ideal for applications that require fast and accurate search functionality.
- Due to its horizontal scalability, it allows for adding more nodes to the cluster to accommodate growing data and query loads.
- Provides real-time indexing and search capabilities, making it suitable for applications that require up-to-date data.
Cons:
- Setting up and configuring Elasticsearch can be complex, especially in large-scale deployments.
- Running Elasticsearch requires significant CPU, memory, and storage resources.
- May not be the best choice for applications requiring strong durability guarantees.
Use cases: log analysis, infrastructure monitoring, e-commerce search
ClickHouse
ClickHouse is an open-source columnar database management system designed for analytics and data warehousing. It is known for its speed and efficiency when working with large datasets, making it a popular choice for analytical workloads.
Pros:
- One of the fastest modern databases for analytical queries due to its columnar storage and efficient query execution.
- Offers excellent data compression, allowing organizations to efficiently store large amounts of data.
- Supports SQL queries, making it accessible to users familiar with SQL.
Cons:
- Primarily suited for analytical workloads and may not be the best choice for transactional or OLTP applications.
- Setting up and configuring ClickHouse may require expertise, especially in distributed deployments.
- Data ingestion might not be as fast as in other systems designed for real-time big data processing.
Use cases: analytics and reporting, data warehousing, IoT applications

Choosing a database management system for your unique project requirements?
Yalantis offers expert guidance in selecting and implementing the ideal database solutions for your specific needs.
9 database management systems compared
Below is a detailed comparison of the best database management systems we discussed earlier based on data integrity, performance, best use cases, and beginner support.
|
Database |
Type |
Data integrity |
Performance |
Best use cases |
Beginner support |
|
PostgreSQL |
Object-relational (SQL) |
ACID |
High for frequent and concurrent write operations; requires memory-intensive resources to scale for multiple users |
Financial apps, analytics systems, and healthcare data platforms |
Moderate community onboarding, excellent documentation; requires SQL and DB tuning basics |
|
MySQL |
Relational (SQL) |
ACID |
Good general performance for read-heavy apps; bottlenecks on complex joins and large datasets |
Web applications, CRM, e-commerce |
Good for beginners, widely used in tutorials, strong documentation |
|
SQLite |
Embedded SQL |
ACID (limited) |
Moderate performance; ideal for local lightweight applications but not for concurrent or large-scale data |
Mobile apps, IoT, embedded systems |
Very beginner-friendly; minimal setup and easy API |
|
Microsoft SQL Server |
Relational (SQL) |
ACID |
High performance for enterprise-grade OLTP and analytics; resource-intensive at scale |
Corporate data systems, enterprise analytics |
Steeper learning curve; GUI tools help, but setup complexity is high |
|
MongoDB |
Document store (NoSQL) |
BASE (with optional ACID) |
High performance on flexible schema and unstructured data; indexing and memory usage affect write speed |
Content management, mobile backends, product catalogs |
Moderate; flexible, but querying data requires learning new paradigms |
|
Oracle |
Multi-model (SQL) |
ACID |
Very high throughput, optimized for heavy transactional systems; resource-intensive setup |
Banking systems, ERP, telecom |
Challenging for newcomers; enterprise features and complex setup |
|
Redis |
Key–value store (NoSQL) |
BASE |
Extremely fast for in-memory operations; best for caching and ephemeral data, not persistent storage |
Caching, real-time chat, and leaderboard tracking |
Simple to start; commands are intuitive and widely documented |
|
Elasticsearch |
Document store (NoSQL) |
BASE |
Excellent for full-text search and analytics; slower on large joins or real-time updates |
Log analytics, monitoring, and search systems |
Moderate difficulty; requires understanding of indexing and cluster configs |
|
ClickHouse |
Columnar (SQL) |
Partial BASE (eventual consistency) |
Very high performance on analytical queries due to columnar storage; not optimized for transactional workloads |
Business intelligence, reporting, and IoT analytics |
Advanced, best suited for experienced engineers in analytics setups |
Mixing and matching databases for your needs
Using several databases for one project to take advantage of the strengths of each is a common practical solution to address specific project requirements. However, developers should make this decision after carefully analyzing and defining the product’s technology stack.
For instance, you might use a relational database like MySQL or PostgreSQL for storing and querying structured data while incorporating a NoSQL database like MongoDB for flexible and scalable storage of unstructured data (medical images, emails, social media mentions). This hybrid approach allows you to optimize your data management strategy based on the specific needs of different data models of your application.
However, not all database matches work seamlessly. If you plan to create an environment that consists of two or more database platforms, you should consider the following:
- Data consistency and integrity. If the data management process is not properly synchronized, it can lead to inconsistencies across multiple databases. It’s essential to implement robust mechanisms for data integrity and consistency, such as distributed transactions or eventual consistency models, depending on the use case and database technologies involved.
- Data complexity and maintainability. Using multiple databases increases the complexity of the system architecture. Careful design and documentation are necessary to mitigate these challenges, ensuring that the system remains manageable and that developers understand the interactions between different databases.
- System performance and scalability. Different databases may have different scaling capabilities. Considerations here include how each database handles read/write operations, its scalability in terms of data volume and query complexity, and the overall impact on application performance.
- Data access patterns. Different databases often come with their own querying languages and APIs (SQL for relational databases, Cypher for Neo4j, the MongoDB query language). This means that your project must accommodate different data access patterns, such as transactions in relational databases or flexible document access in NoSQL databases.
- Security and compliance. Each database system may have its own set of security features and compliance standards. It’s important to ensure that all databases in the project adhere to the required security protocols, such as data encryption, access controls, and auditing.
The choice of the database for your project depends on many factors, including the types of data you’re going to collect and process, integrations with other tools, and the scaling approach you follow. It’s not just a question of SQL or NoSQL, as many think.
And even though proper data management may not be the first thing you consider when optimizing the user experience, it definitely should be. We can help you find the best possible database solution for your web or mobile solutions. Drop us a line if you want us to help you in selecting the right database for your needs.
Discover what data technologies we’re good at
We can help you create a flexible and scalable app with a secure data architecture
FAQ
Which database solution is most reliable for mobile apps that experience variable user traffic?
It’s advisable to opt for NoSQL databases due to their scalability, flexibility, and ability to handle large volumes of unstructured data. SQL databases can be a good choice if your app requires complex queries and transactional integrity, but they often have performance issues with large amounts of data.
What is the ROI difference between SQL and NoSQL databases?
SQL databases often have higher upfront costs due to infrastructure and maintenance, but they offer long-term ROI through data accuracy, compliance, and mature ecosystems. They reduce risks in industries where mistakes are costly (e.g., healthcare, banking).
NoSQL databases can deliver faster ROI for high-growth, content-heavy, or less regulated apps thanks to lower initial overhead, faster development cycles, and easy scalability. Ultimately, ROI depends on how well the database aligns with your app’s performance needs, complexity, and growth needs, not just on the database type.
How does database choice impact product time-to-market?
Your database affects how quickly you can build, test, and scale your product. NoSQL databases allow faster iteration during development due to their schema flexibility. They’re ideal for MVPs, evolving requirements, and agile teams. SQL databases take more time to set up and enforce strict and complex data models, but they reduce downstream risks by ensuring consistency and integrity from the start.
Choosing a database that matches your current development speed and future scaling needs can significantly shorten the path to launch and help avoid costly rework later.
About the author