



A software system’s architecture is its backbone, and depending on how that architecture is designed, it can either support the system or crash it. A solution architect should have a holistic view of how to transform your business goals and requirements into a stable architecture. After all, it’s a project’s architecture that drives the choice of the technology stack, not the other way around.
The solution architect has a wide scope of responsibilities. We’ll cover only the most important, mainly regarding the business part of project execution. Plus, we’ll point out specifics of mainstream architectures.
To ensure you get an elaborate and structured solution architecture, you need to work with a professional and know how to assess their work. Let’s define the role and competencies of a solution architect.
Software architect role and skills
The software architect may take part in all project stages depending on the project’s size and duration. However, the most crucial in terms of selecting a software architecture and preparing an architecture solution are the presale and discovery stages. During these stages, a software architect works together with a business analyst to properly organize software systems. For more on this partnership, explore our detailed article on the role of the business analyst.
At the presale stage, a software architect defines:
- project needs, i.e. what the project is about
- business goals, such as building a new product to increase revenue
- functional and technical requirements, i.e. functionality the software will have
- non-functional requirements, i.e. product attributes like reliability, maintainability, and scalability
- risks that may be realized throughout the project, such as issues with scaling services
- concerns like whether the client’s business requirements are feasible
- technical constraints, such as the necessity to migrate from on-premises software to the cloud architecture
- business constraints, such as compliance with HIPAA requirements for healthcare products and PCI requirements for FinTech
At the discovery stage, a software architect:
- takes part in preparing a proposal for the client
- creates the architectural vision and software architecture design
- works on the roadmap and project estimate
- contributes to selecting the team
Try also to explore our article about digital banking architecture.
Mark Richards, a hands-on software architect and the author of many books on software architecture, defines the soft skills and knowledge a solution architect should have as follows:
- Leadership and communication. An architect with good communication skills knows how to explain and justify their architecture decisions to all the project stakeholders, with a tech background or without.
- Tech knowledge. Obviously, a software architect should have in-depth knowledge of the technologies they work with daily. But a proper architect should also have a growth mindset and get familiar with new technologies that are constantly emerging. This doesn’t mean becoming an expert in all the new technologies, but simply being aware of their capabilities can help a software architect make better architectural decisions.
- Business domain knowledge. Each business has its jargon, notions, trends, and competitors. A solution architect should explore these areas of the business they’re working with. Only by being aware of business specifics can a solution architect provide a reliable and relevant architecture. Besides, business awareness simplifies communication between stakeholders and the solution architect and makes the latter appear more trustworthy.
A software architect is a technical expert with a comprehensive understanding of the business. And business requirements are the glue of software architecture design (SAD).
Read also: How We Deal with the App Development Process at Yalantis
How does a software architect process your business requirements?
Eliciting and processing requirements is one of the preliminary steps a software architect takes before developing a software design.
A software architect decomposes business requirements for your project into the following components:
- functionality
- constraints
- quality attributes
Quality attributes are characteristics the software should have. Here are a few examples of the most common quality attributes:
- Functional suitability. Does the system functionality cover your users’ objectives and needs?
- Performance efficiency. How long does it take for the software to launch and process key functionality?
- Compatibility. Can the system easily exchange data with other systems, products, or system components?
- Usability. Can users easily navigate the system?
- Reliability. Is the system fault-tolerant? Can users access it whenever needed?
- Security. Is the system secure enough and can it store users’ data securely?
- Maintainability. How easy is it to modify, test, or improve the software product?
- Portability. Is the system adaptable to different environments? (e.g. Can it work on different operating systems?)
Each software product has its crucial quality attributes. For example, for a FinTech business application, security is most important, whereas it’s less critical if the app isn’t available 24/7. Just as you can’t put your whole wardrobe in one suitcase, you can’t ensure all quality attributes for one product, as each product has its limits. You have to prioritize.
A software architect uses the following methods to process quality attributes:
- A quality attribute workshop (QAW) helps with generating and prioritizing quality attributes and involves discussion with all project stakeholders
- Attribute-driven design (ADD) allows the software architect to define the type of software architecture and model of the software based on the project’s quality attributes
- The architecture tradeoff analysis method (ATAM) evaluates the architecture design resulting from the ADD method

Additionally, ATAM helps you check whether an architecture design fulfills business goals and quality attributes. This method is also referred to as the risk identification method to help you identify and prevent risks in the early stages of the software development life cycle (SDLC).
ATAM includes the following components:
- Risks are inefficient or unmade architectural decisions for a particular project
- Tradeoffs or priorities of the quality attributes mean that, for example, we can ensure the high performance software at the expense of security
- Sensitivity points are the results of favorable architectural decisions that lead to the realization of the desired quality attributes
With the help of the above-mentioned methods, a software architect knows how to choose the right software architecture.
Read also: Secure Application Development: From Planning to Production
Software architecture types
There are many types of software architectures that fulfill all kinds of business goals. We’ll take a look at the most common, cover their pros and cons, and define for which businesses each is the most suitable.
Monolithic architecture
This architectural pattern is one of the most inconvenient in terms of many attributes, especially maintainability, scalability, and flexibility. In a monolithic architecture, all software components are combined into a single codebase.
Pros of the monolithic architecture:
- Quick development
- High performance of the software system
- Good for startup projects
Cons of the monolithic architecture:
- Hard to change software frameworks, libraries, and languages of different system components
- Hard to scale when the project grows and more functionality is added
- Failure of one service can lead to failure of the whole system
- Issues with work coordination if the development team is large
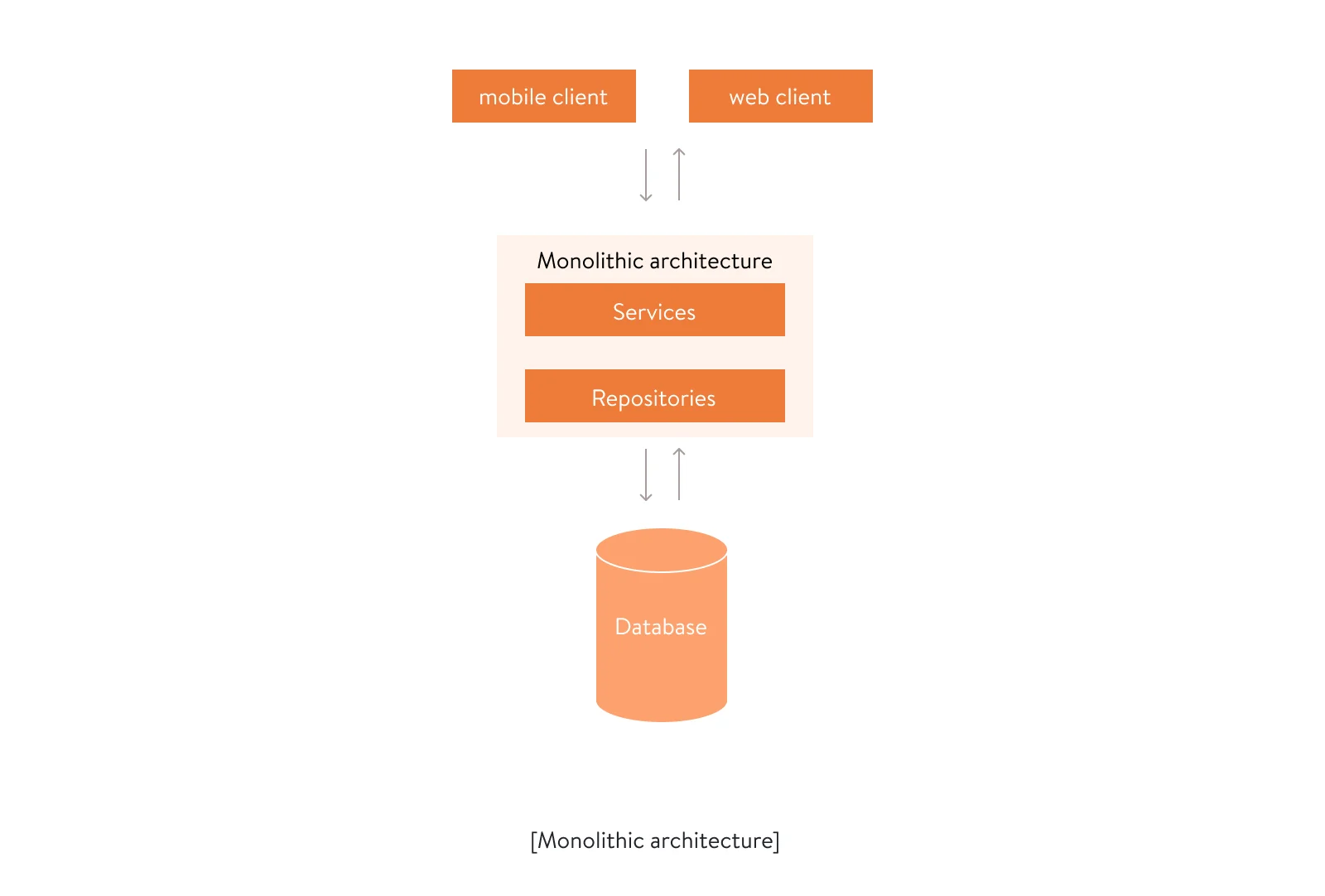
Where you can use it: A monolithic architecture works best for small projects with relatively small development teams that need to show the project value fast. For instance, Flickr and Etsy have small development teams and manage to have good monolithic architectures for their websites.
Layered architecture
A layered architecture can suit a variety of software products. With this architecture, the application’s codebase gets split into three main layers, each performing its specific function:
- The presentation layer, or the front end of the software product, is responsible for presenting information to users
- The business layer, or the back end of the software product, is responsible for driving all the application capabilities and business logic
- The database layer contains all the data the product operates with
All software requests in this architecture flow down from the presentation layer to the database layer. Each layer is closed, meaning that each request has to go through all layers one by one in order to get to the last. Thus, a request coming from the presentation layer can’t skip the business layer and directly retrieve data from the database. Such a structure is also called isolation of layers and simplifies the development of each layer, allowing you to make isolated changes to each layer if necessary.
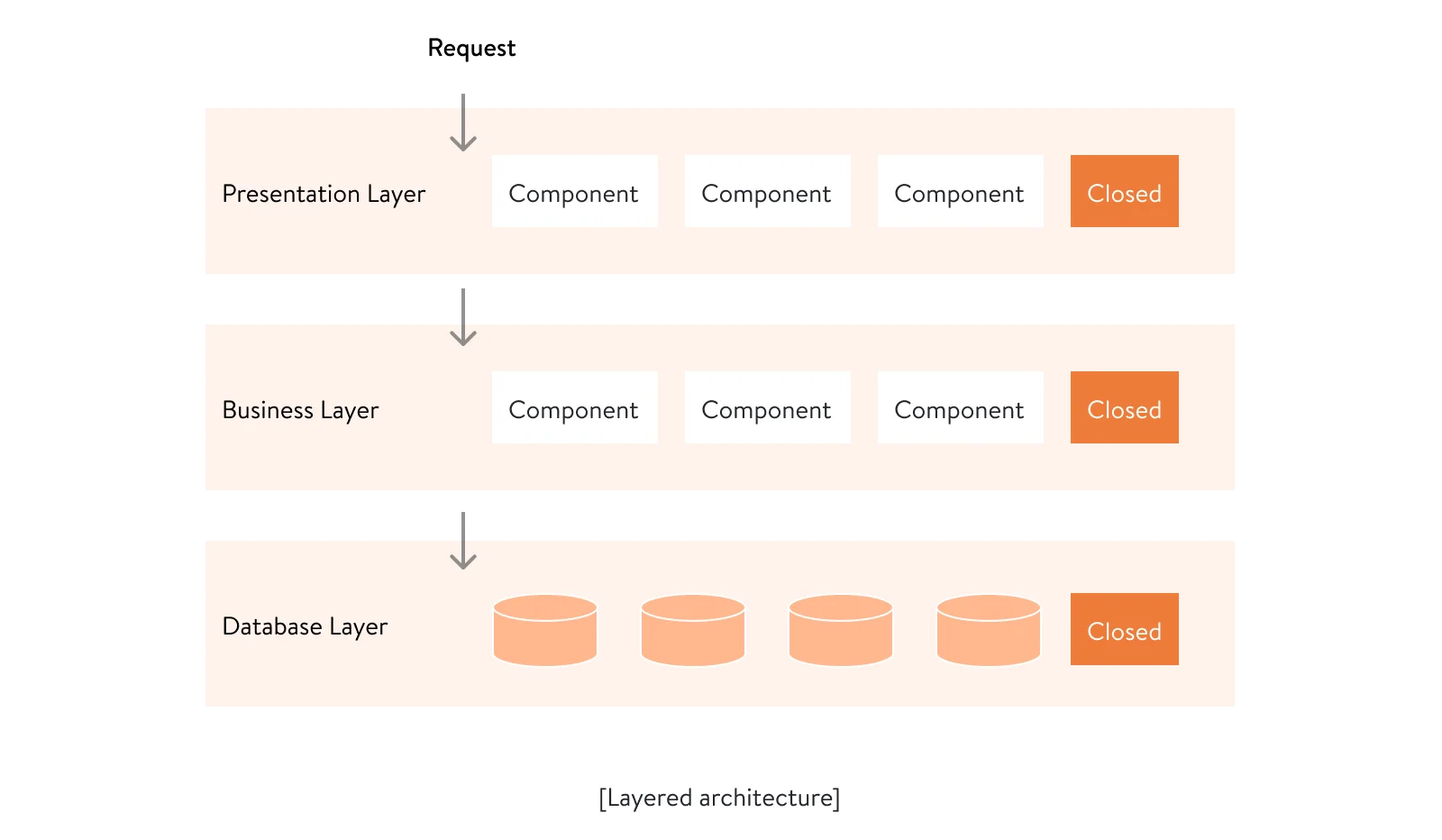
This type of architecture also allows for adding open layers in between closed ones to avoid the architecture sinkhole anti-pattern. This anti-pattern may happen if, for instance, a business layer doesn’t perform any significant function but simply passes requests to the layer below. If this is the case, a software architect can make that business layer open. An open layer can be skipped if not necessary for certain requests. However, open layers impact the overall isolation of layers and can lead to the coupling of certain layers into one codebase.
Pros of the layered architecture:
- Easy to develop, test, scale, and maintain thanks to layer isolation
- Different layers can be built with different technologies, allowing for changes to be made to one layer without affecting others
Cons of the layered architecture:
- Still not optimized and scalable enough as the project evolves
- The time-consuming flow of each user request through all layers slows down system performance
- The more layers appear in the system, the harder it becomes to maintain it
Where you can use it: A layered architecture is suitable for new software products that process a small number of user requests and don’t require high performance.
Read also: Explore the Type of Successful Architecture We Built for an Energy Consumption Management System
Event-driven architecture
This is an asynchronous and decoupled architectural pattern. An event-driven architecture (EDA) processes events (state changes) that happen inconsistently in the software system. For example, an event can be when a patient books an appointment with a clinician on a hospital website or when a user buys a product on an e-commerce site.
An event-driven architecture includes event producers, event transport, and event consumers. For example, in a retail web application, we might have a checkout service as an event producer and inventory, shipping, and contact services as event consumers. A producer publishes an event in the event transport which, in turn, transfers the event to the consumer.

Pros of the event-driven architecture:
- Highly distributed and highly scalable, as event producers and event consumers are decoupled and it’s easy to add new consumers and producers to the system
- The existence of event transport eliminates the need for direct communication and dependencies between producers and consumers
- Ensures high performance and quickly processes real-time data, as consumers can immediately respond to events
Cons of the event-driven architecture:
- Hard to trace the event path (e.g. event consumers don’t get data on which producer produced an event) without proper documentation
- Unclear event flow makes it difficult to test this architecture
- If an event transport fails, the whole system fails
Where you can use it:
- IoT systems. In IoT, events are sensor readings, and once event consumers receive them, users are notified to take a certain action. For example, in a warehouse, if sensors that track temperature capture a temperature drop, logistics managers can get notified.
Read also: Why consider IoT testing services?
- Supply chain management systems. Logistics companies that process e-commerce orders can also benefit from the integration of an event-driven architecture. For instance, when a user places an order on an e-shop (i.e. creates a “new order” event), a warehouse management system (WMS) built with event-driven architecture (EDA) can receive this event through the event transport and immediately update the stock of requested goods.
- Real-time chats. An event-driven architecture also fits well for a messaging mobile application with frequent real-time updates.
Read also: How to Create a Really Great RESTful API
Microservices architecture
The microservices architecture is a trendy architectural pattern in the software engineering industry. Under a microservices architecture, all services of the software system are loosely coupled and independent of one another. As an example, check out the delivery and logistics project we developed with a microservices architecture. For insights on digital trade promotion management strategies, explore our dedicated article that delves into optimizing promotional campaigns.

Pros of the microservices architecture:
- Scalable. With the microservices architecture, you can decide how software applications can scale. Scalability is possible at the level of services, as you can enhance the capabilities of one service but leave others as is.
- Modifiable. This type of architecture also allows for making changes to each service without impacting others, such as implementing any new technology or changing a service’s framework, library, or language.
- Maintainable. The microservices architecture simplifies the process of handling issues and service optimization. If, for example, your email service needs to be fixed, you can quickly do so without impacting other services. Thus, if one of your components fails, the whole system won’t.
- Suitable for large development teams. With microservices, different teams can work on different services and focus on different system factors. Such organization of work simplifies project coordination and makes remote collaboration more efficient.
Cons of the microservices architecture:
- Testing a whole bunch of services can be cumbersome
- Software performance may be affected, especially if there are many services in this architecture
Sam Newman, the author of famous books on software architecture such as Building Microservices and Monolith to Microservices gives three reasons to choose microservices (and a use case for each reason) in his interview with Martin Fowler.
Reason #1. Zero-downtime independent deployability of services
For example, a microservices architecture can be suitable for SaaS businesses that need their systems to work consistently and can’t tolerate failures. Yet this type of architecture also works well for any industry where fault tolerance is of the highest priority.
Reason #2. Isolation of processes around data
In this respect, a microservices architecture is beneficial for healthcare organizations that need to comply with GDPR, HIPAA, or other laws and regulations. With this architecture, services that handle protected health information (PHI) can be managed more strictly than other services. On the other hand, services that don’t deal with PHI can be managed less strictly and not even exchange data with services that handle PHI.
Read also: HIPAA Compliance Checklist: Steps to Take to Become HIPAA-Compliant
Reason #3. High degree of organizational autonomy
The microservices architecture also fits well for companies that need to form self-managed teams that take full responsibility for their work. This approach aims to reduce the amount of coordination required between a development team and the rest of the organization. For example, Atlassian fosters autonomy in their teams, calling them “loosely coupled but tightly aligned.” Behind this organizational approach stands the belief that self-disciplined and autonomous teams can significantly contribute to the company’s progress.
In this article, we’ve compiled key characteristics of the most common architecture types to help you decide which will best fit your project. Below, you can check out a table that compares these software architecture patterns based on a high (↑) or low (↓) degree of the most common project attributes.
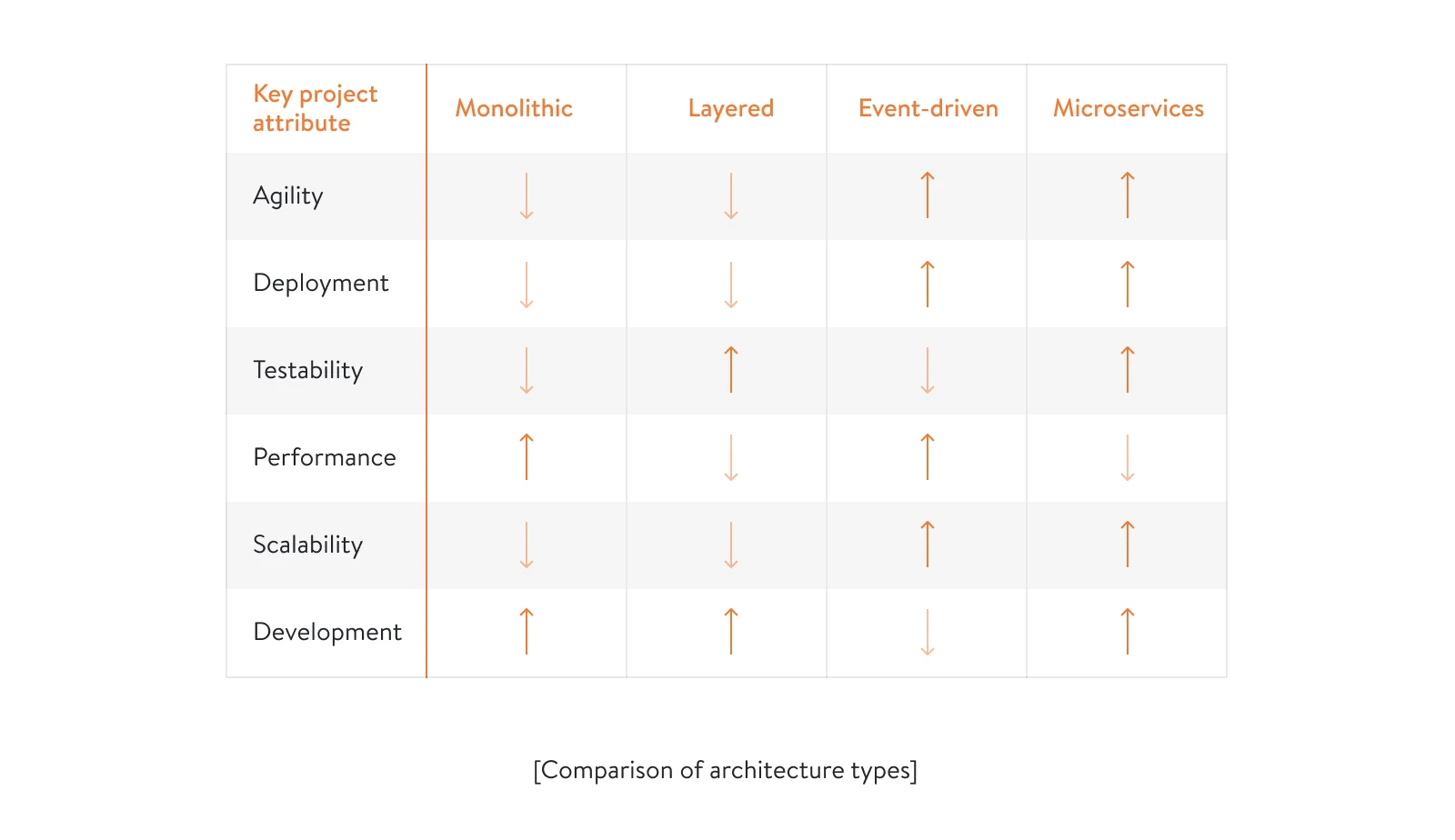
As your business idea or goals change, your architecture can change too. At first, a monolithic architecture may be sufficient to fulfill your goals. But once you realize your business has outgrown it, you can switch to an event-driven or microservices architecture. It’s also possible that your solution architect may create a hybrid architecture for your project to cover more of your business needs.
To implement the proper software architecture, you’ll need to closely cooperate with your solution architect. The more detailed the project requirements you provide, the more suitable the software architecture your architect can design for you. A software architect’s experience, of course, also contributes to your project’s success.
At Yalantis, we pay close attention to the skill set and experience of our solution architects to ensure they add value to projects (we work on 72+ projects annually). So far, our architects have helped our clients:
- switch a twenty-year-old monolithic project to microservices
- successfully migrate from on-premises to the cloud with refactoring strategy
- eliminate core system bottlenecks that restrained performance
- reduce operating costs
This list could be extended, as we treat each project as a unique story and always search for a tailored approach. Learn more about the services we provide to develop software products that elevate business performance.
Want an architecture that fits your business needs?
Choose our experts
About the author





