


Once you figure out a suitable way of collecting, storing, managing, transforming, analyzing, and then using your data (such as a data lake), you will be able to improve lots of your internal operations. For example, the 2024 global KPMG survey of 2,450 executives ranked data and analytics as the leading driver of tech-related profitability. The majority (89%) of them reported a positive impact of data and analytics initiatives on the organization’s bottom line.
New data analytics opportunities allow businesses to generate more revenue, make better strategic decisions, and tell compelling stories to their customers. To consolidate all of their data assets in a single place, successful businesses implement data warehouses, data lakehouses, and data lakes. In this blog post, we dive deep into the concept of data lakes.
We discuss the benefits of a data lake for your business, explain data lake architecture and use cases, and provide you with a table comparing several popular tools to help you choose the best data lake provider based on your budget, functionality, and integration preferences. We also briefly compare data lakes with data warehouses to give you a general understanding of how data lakes stand out.
What Is a Data Lake and How Does It Work?
A data lake is a centralized data repository that can combine all types of data — structured, unstructured, and semi-structured — and allows for simple data retrieval and further use for advanced data analytics solutions. With the help of a data lake, businesses can better manage big data streams from both inside and outside sources, maintaining a comprehensive understanding of the state of affairs within the business. It’s a much better option than storing data in siloed databases scattered across departments.
What’s the working principle of a data lake? Compared to data warehouses, data lakes can store much larger amounts of data (and different types of data). In fact, the need for data lakes appeared due to the limited capabilities of a data warehouse.
To be put into a data lake, data doesn’t need to be transformed and can stay in a raw format, which significantly increases the speed of data ingestion compared to an enterprise data warehouse. While data warehouses work based on an extract, transform, load (ETL) engine, data lakes use the extract, load, transform (ELT) pattern, as they transform raw data only upon request but not immediately after data extraction as data warehouses do.
Why and When Should You Use a Data Lake?
With a data lake, you can store any data together, reducing data storage costs and enabling new analytics capabilities that a data warehouse cannot support. However, having both types of data repositories can be beneficial, as data warehouses have a more convenient data structure for business intelligence and historical data analysis.
A data lake can be the right option for you if your business goals include the following:
Improving real-time data aggregation from diverse sources. If your company has lots of sources of incoming data such as IoT sensors and devices, customer data including reviews or surveys, social media, and corporate systems, then implementing a data lake can be a viable option (e.g., a customer data lake). Plus, a data lake is extremely scalable (making it able to ingest lots of data) and can be optimized for low-latency queries and data retrieval. Additionally, implementing a data lake can allow you to combine all critical business data assets in a single storage place and help you conduct better root cause analysis to quickly uncover cross-company issues.
Enabling big data processing and analytics. Data lakes store all types of structured, unstructured, and semi-structured data and can easily integrate with advanced analytics and machine learning tools, allowing data scientists to efficiently perform deep data analysis. However, if implementing advanced data analytics seems complicated to you, consider Yalantis’ vast data science services to ensure this process is seamless and beneficial for your business.
Effectively using machine learning algorithms. The majority of data lake providers mention that data lakes can be particularly useful for data scientists, data engineers, and AI engineers for data exploration and model training purposes. Primarily, this is because data lakes provide access to big data sets that are comprehensive and complex enough for training and building accurate and effective machine learning algorithms (use cases for machine learning). Plus, data lakes don’t have predefined schemas (used mostly for organizing data in relational databases and data warehouses) and offer more flexibility.
Seamlessly and cost-effectively integrating with a cloud environment. Transitioning your IT infrastructure from on-premises to the cloud can also include shifting most of your proprietary data into a data lake. Most cloud services vendors such as Amazon provide cost-effective and scalable solutions. Maintaining a data lake on-premises can be difficult in terms of dealing with hardware failures, for instance, as a data lake handles large datasets and requires high computational power.
Domain-Agnostic Data Lake Integration Capabilities
For their State of Cloud Software Spending report, Battery Ventures surveyed 100 chief experience officers (CXOs) in financial services, technology, healthcare, and manufacturing. Below, you can see a table from this report showcasing what aspects of data management companies prioritize the most in 2024. We can see that data warehousing and data operations account for over 15% of the surveyed organizations’ tech budget. When you establish an efficient data storage solution, all other aspects of the data infrastructure, such as data governance procedures, data visualization capabilities (data visualization services), data applications, and real-time data management, fall into place.
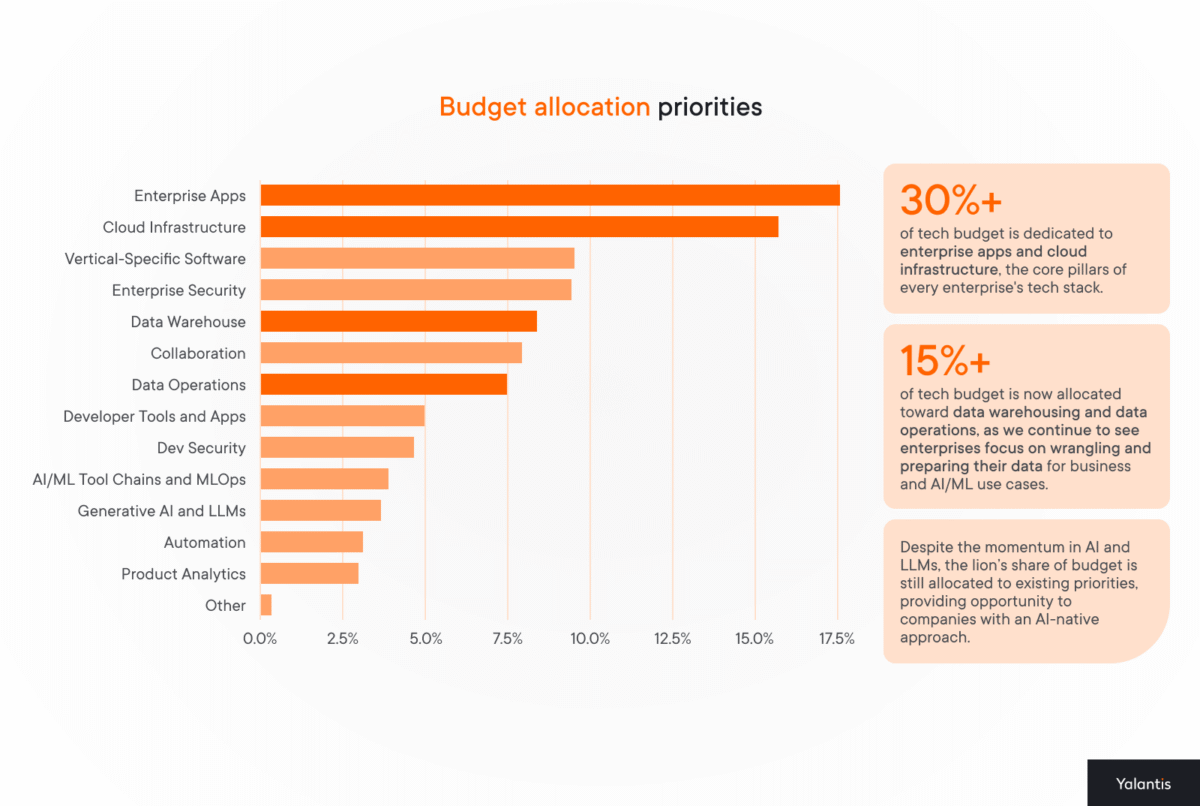
The investment in data is also expected to increase, with 80% of surveyed CXOs planning to spend more on data operations within the next five years.
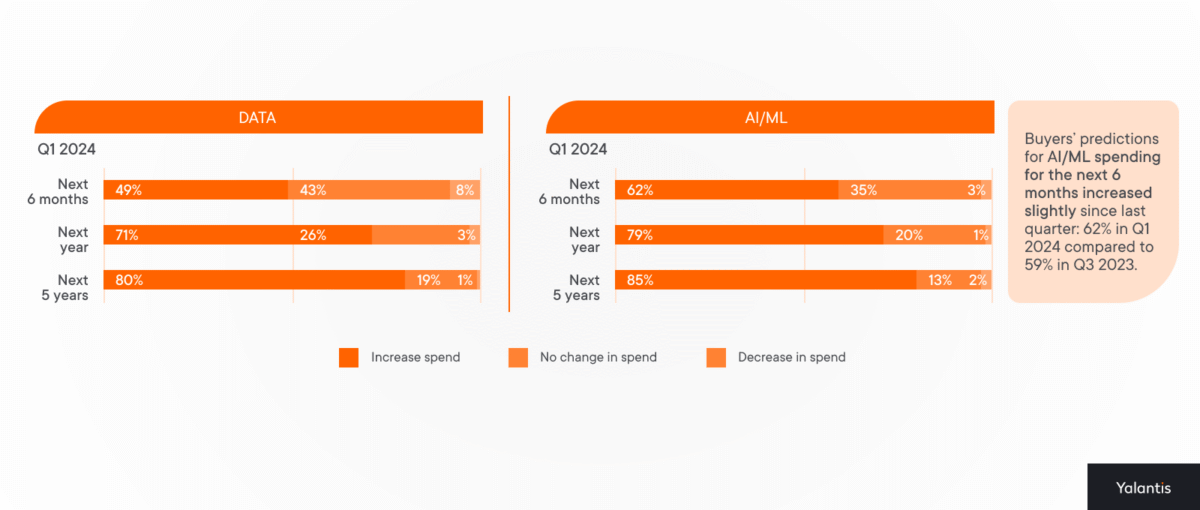
If you need your data to offer more insights than it does now, investing in a data lake can be advantageous.
Data Lake Architecture
Implementing a data lake requires putting six key components in place. Together, they comprise the conventional data lake architecture. Let’s break them down:
- Data sources. Your data lake can pull structured, unstructured, and semi-structured data from internal and external sources. Common sources include CRMs, ERPs, social media, IoT devices, and relational databases.
- Data ingestion. These are the extraction and loading processes that take the created data and add it to the data lake. Data can be ingested in batches or in real time, depending on your needs, using APIs and data integration platforms.
- Data storage and processing. The raw data ends up in the data lake’s so-called landing zone. It’s then transformed in a separate section and transferred to the refined data section.
- Analytical environment. Also known as the analytical sandbox, this layer enables data exploration, discovery, and use for machine learning and data analysis. It’s separated from data storage to prevent data quality degradation.
- Data consumption. This layer presents data and insights in a user-friendly manner by supplying them to business intelligence tools such as Power BI and Tableau.
- Governance and security. This all-encompassing layer defines and enforces the rules for data access, sharing, security, and quality. It also includes monitoring tools and data stewardship.
N.B. This is a general data lake architecture that may need to be tweaked for your specific data lake uses. To make high-ROI architectural choices, make sure you have the right data expertise when preparing the project to navigate different types of data lake architectures.
What Challenges Does a Data Lake Solve?
Any enterprise struggles with data management and quality in one form or another. Here are the five challenges data lakes are well-positioned to resolve:
- Data silos. This challenge is on the rise, going up seven points since 2023, according to Dataversity. Data lakes can centralize raw data from diverse sources, from emails and social media to internal relational databases, essentially serving as a single source of truth.
- Data variety. Traditional databases and even data warehouses are great at aggregating structured data, but they can’t handle unstructured data. Yet, an estimated 80% to 90% of all enterprise data is unstructured. Data lakes can handle all data types, enabling a data strategy for all data types (which only 16% of organizations currently have in place).
- Storage costs. When your data estate grows to petabytes upon petabytes, data warehouses and other storage solutions can become too costly. Data lakes provide a more cost-efficient alternative, provided they’re optimized for cloud storage platforms.
- Scalability. As the volumes and variety of data increase, data challenges become a substantial bottleneck for advanced analytics. For example, data preparation represents the number one bottleneck for AI projects. Data lakes enable analytics tools to process large data volumes thanks to enhanced performance coupled with elastic scaling.
- Real-time access. Other data repositories require transformations to take place before data is loaded into them, representing a potential bottleneck for real-time data streaming. Data lakes, in turn, support schema-on-read, which means data is transformed upon query.
Data Lake Benefits
Moving from the reasons for adopting a data lake, we should cover how you can benefit from its implementation. Here are a few common and uncommon data lake benefits:
Long-Term Data Preservation
No datasets get lost or missed if you use a data lake. This type of data repository allows you to store all data your organization produces for the sake of further use during extensive data analysis. With a data lake, you don’t have to know all the use cases for your data right away but can simply store it for future data analysis. Leveraging a data and analytics implementation service helps ensure that your data lake is optimized for seamless integration and efficient data retrieval, making it ready for in-depth analysis at any time.
Flexibility and Scalability
As you acquire more software solutions and devices for streamlined service delivery or improved business process management, a data lake has your back with its vast storage capacity. With less strict rules for storing data compared to data warehouses, the advantages of data lakes include more flexibility and simple data query and retrieval.
Enhanced Customer Service
Collecting miscellaneous customer data including purchasing choices, digital behavior, presence and level of activity on social media platforms, and feedback about your company or services can help you come up with personalized services, recommendations, and products during the data analytics process, thereby significantly increasing customer loyalty.
Vast Data Exploration and Research Capabilities
Storing and processing large amounts of data can unveil previously unknown business insights and help you conduct deep-dive marketing and business research. In this way, and with support from a big data company, you can better match your products and services to current customer needs.
Reduced Overhead and Capital Expenses
Among the many advantages of a data lake are the fact that it’s a scalable, cost-efficient solution that centralizes large and varied datasets in a single storage space and provides self-service data access. Thus, implementing a single data lake can help you save energy, eliminate the need to hire more data engineers, and establish additional data storage systems to match the increasing business data flow.
Improved Business Continuity
Another benefit of a data lake is the ability to implement it as a single storage system to speed up your service delivery and maintain proper business continuity. For instance, Grand River Hospital rolled out a data lake on AWS and managed to migrate almost three terabytes of patient data. Thanks to this migration, they no longer needed 27 diverse healthcare applications. The data lake also allowed the hospital to use their data efficiently and economically.
Data lake advantages aren’t limited to those described above, as each business is unique. To receive the most value, you should consider integrating a custom data lake solution that fits your business routine and fulfills all of your needs. In the next section, we cover use cases where a data lake is an absolute necessity.
Data Lake Use Cases with Examples
Implementing a data lake is not new or progressive, but as data lakes improve we can find more and more applications for them. Let’s discuss data lake use cases to see how you can efficiently use data lake solutions in different business scenarios.
Always-On Business Services
Real-time data ingestion allows data lakes to make any business data available at any time and upon request. For instance, mission-critical software like banking applications and clinical decision-making software need to function 24/7 to allow users to perform financial operations and transactions without interruption.
For example, data lakes can enable real-time fraud detection in finance and banking around the clock. Or, they can supply the data necessary for real-time cybersecurity threat and incident detection.
360-Degree Customer Overview
Rolling out a data lake can help you aggregate all available customer data in a single storage space and enable all-around tracking of your customer data to offer customers timely services and increase customer lifetime value (CLV).
The advantages of data lakes don’t stop at the conventional CX personalization. Data lakes can also enable natural language processing for real-time sentiment analysis, which can help you instantly identify CX issues as they occur.
For instance, the German online retailer Zalando decided to transition to a data lake to avoid storing customer data in legacy data warehouses and scattered databases across the company and enable simplified data querying for their business analysts and data scientists.
Real-Time Risk Control
To comply with laws and regulations, businesses in different industries need to constantly monitor their data storage and data processing practices. With a data lake, conducting compliance monitoring is much easier, as you can rapidly overview large amounts of cross-functional data at one time. Overviewing data scattered across disparate databases and data warehouses can be time-consuming, prolonging regular compliance checks.
Besides facilitating regulatory compliance, data lakes can also consolidate data relevant for risk management from multiple sources. This can come in handy in risk assessments for loan and insurance underwriting, insurance claims processing, and real-time fraud and financial crime detection.
IoT Ecosystem Management
Data lakes are also beneficial if you have a large IoT ecosystem that regularly generates lots of data. This data is often unstructured and can be further used for advanced analytics, and a data lake can easily collect and store such data so you can use it whenever necessary. For instance, IoT devices provider Samsara uses a data lake to have sufficient reliability and scalability for querying data and performing large-scale data analysis.
The collected IoT sensor data can power, for example, predictive maintenance for equipment via an industrial data lake and prevent downtime. This is what our logistics data lake solution did for a manufacturing company. In energy and utilities, in turn, IoT data can be used to forecast and match energy demand and supply.
As we’ve already discovered the benefits of a data lake, use cases for data lake solutions, and reasons to adopt a data lake, we can proceed to comparing common examples of data lakes to help you make a balanced decision by analyzing the critical characteristics of each data lake.
Building a Data Lake: Overview
To build a data lake solution, you need to design a comprehensive data architecture, taking into account data sources and types. A proper data architecture is critical to ensure seamless data aggregation, storage, and transfer by using diverse technologies. The choice of technologies largely depends on the combination of your technical team’s skills and expertise as well as your business requirements.
Plus, data lakes have a separate storage and retrieval flow for different storage classes:
Hot data that is used repeatedly and accessed regularly
Cold data that is used occasionally
Archived data that is no longer in use and is only necessary for rare reviews
Let’s explore how to build a data lake.
Popular Data Lake Platforms Comparison
In the table below, we compare five popular data lake providers in terms of pricing, functionality, and setup difficulty. We have filled this table based on information available on each vendor’s website and the G2 platform, which includes thousands of real user reviews.
|
Vendor |
Pricing |
Feature highlights |
Implementation difficulty |
|
Amazon Simple Storage Services (S3) |
AWS S3 has nine different storage classes and offers a free trial (5 GB of S3 Standard storage). The standard plan includes 50 TB of data per month at the price of $0.023 per GB. The price varies based on the selected region. |
|
High |
|
Azure Data Lake Store |
Free trial ($200 credit) and separate pricing for premium, hot, cool, cold, and archived data storage (the first 51 TB of hot data is $0.021 per GB; prices vary from region to region). |
|
Moderate |
|
Google Cloud Storage |
Price varies depending on the region and storage type (standard/nearline/coldline/archive/anywhere cache); free trials available for new products and customers ($300 in free credit). The free tier is available for 20+ cloud services. The price range for standard storage is from $0.020 to $0.023 (US) / $0.025 (EU) / $0.035 (Brazil) per GB per month. |
|
Moderate |
|
Snowflake Data Lake |
30-day free trial ($400 worth of free usage) for all products. No open pricing information for the data lake solution. |
|
Moderate |
|
IBM Cloud Object Storage |
Free trials (25 GB per month storage; $200 in free credits for 30 days) and 40+ always-free products; custom payment plans. Free tier available (5 GB / month). The standard plans for hot data is on average $0.0219 per GB per month. |
|
Moderate |
Cost. Establishing a data lake can be more cost-effective than rolling out a data warehouse based on our experience as a data warehousing company. For example, for a data warehouse solution, Snowflake charges $40 per terabyte per month in the US, which comes out to $0.04 per gigabyte. Yet with a data warehouse, you get limited capabilities, especially if your aim is launching big data analytics.
Features. Each data lake example in the table above has particular features to stand out among competitors. Your task is to choose a provider with a feature set that is relevant to your business model. IBM offers an entirely new storage class called smart data storage to offer you more flexibility in data distribution. Azure puts particular emphasis on advanced scaling capabilities and acquiring security certifications to be able to service businesses across industries.
Implementation. According to user feedback on the G2 platform, compared to all other data lakes, Amazon S3 and IBM Cloud Object Storage got the lowest scores for ease of setup (8.6 and 8.1 points respectively). As for other vendors, customer reviews on G2 show that competing solutions are moderately complex to set up, with scores ranging from 9.3 (Azure Data Lake Store) to 8.9 (Google Cloud Storage) and 8.9 (Snowflake). Many renowned data warehouse providers such as Snowflake have started offering data lake services to stay relevant on the market and offer their customers an easy transition. So if you already have a Snowflake or an Amazon data warehouse, it might be reasonable cost- and time-wise to consider implementing a Snowflake data lake.
Let’s move from data lake examples to a practical overview of how you can prepare for a seamless data lake implementation.
6 Steps to Implement a Data Lake Successfully
Below, we share six important steps for data lake integration that can make this path clearer and less disruptive for you.
Step 1. Define business objectives. Understand why you need a data lake, what types of data you want to store, and what you want to achieve thanks to data lake implementation. You should also get stakeholder buy-in for this solution and ensure business and technical teams are on the same page.
Step 2. Select a storage solution. Choose a storage solution that fits your data lake development needs. Many organizations opt for cloud-based object storage like AWS S3, Azure Data Lake Storage, or Google Cloud Storage. Your choice can differ from the common variants we’ve discussed in the previous section. Plus, it’s important to ensure that the software company that sets up a data lake for you has experience working with the provider you’re interested in.
Step 3. Design a data architecture. Your data architecture should take into account data ingestion and data governance practices. Data ingestion processes are critical to bringing data from various sources into the data lake. This may involve batch or real-time data ingestion. Your data architect also needs to define data governance policies, including data quality standards, data retention policies, and access controls (data governance policy framework).
Step 4. Organize data processing. Choose data processing tools and frameworks for data transformation, cleaning, and analysis. With their help, it will be easier for you to ensure a seamless big data analytics process. Such frameworks as Apache Spark, Apache Hadoop, and serverless cloud-based services are common choices.
Step 5. Ensure sufficient security. Security measures like encryption and regular monitoring are crucial to protect your data lake from unauthorized access and malicious attacks. For instance, AWS data lake management capabilities include access control lists and access history to keep you up to date with all activity in your data lake.
Step 6. Enable effective data cataloging and discovery. Creating a data catalog makes it easier for data scientists and data engineers to query and understand the data in your data lake. You should also consider establishing metadata management practices to preserve relevant information regarding your datasets.
Final Thoughts
Data lakes are an ideal solution for storing, managing, exploring, and analyzing vast data estates that combine structured, unstructured, and semi-structured data formats. Yet, their unparalleled flexibility is also the main reason why data lake management can be quite complex in the long run.
If a data lake is still a new concept for you, the above recommendations can be helpful. But if your aim is to improve the situation with a current data lake that no longer serves your needs, you should consider consulting our data engineering company to discover all the bottlenecks and come up with relevant solutions.
We’re eager to help you thoroughly prepare your data environment for a streamlined data lake rollout and design a custom and modern data lake solution, considering your unique business needs and requirements.
FAQ
Is cloud storage necessary for a data lake?
Technically speaking, you don’t have to run your data lake in the cloud, but cloud-based deployments offer a number of advantages over on-premises storage. Those include on-demand, unlimited scalability, cost efficiency, and integration with cloud-based AI/ML and other services.
How long does it take to implement a data lake?
The implementation complexity depends on multiple factors, such as the number of data sources, data variety and volumes, and security and compliance requirements. Your data maturity and the state of your current data infrastructure also play a role. Don’t hesitate to get in touch with our experts to discuss how quickly we can have your data lake up and running.
What is the difference between a data lake and a warehouse?
A data lake is better than a data warehouse in certain scenarios because it offers more flexibility and scalability for storing and analyzing diverse data types, including structured and unstructured data. Unlike data warehouses, data lakes can handle large volumes of raw data without the need for upfront data modeling and schema design. This allows organizations to collect and store data from various sources and decide how to structure and analyze it later.
Can small companies benefit from a data lake?
Yes. It’s a common misconception that data lakes are only suitable for large enterprises. These data repositories can also be beneficial for small and medium-sized businesses, but their implementation should align with the organization’s specific data and analytics needs and take into account available computing resources.
What data lake services do you have the most experience with?
We provide data lake services to help organizations capitalize on their big data, enable real-time analytics, and break data silos. As for the technologies we use, we work with Amazon S3, Azure Data Lake Storage, Google Cloud Storage, and Snowflake Data Lake. We also use Apache Kafka/AWS Kinesis for real-time streaming and Apache Flume and AWS Glue for batch ingestion.
Is a data lake suitable for small and mid-sized businesses?
It depends on the data estate the business is dealing with. For example, data-driven companies, such as AI/ML startups, can leverage the benefits of data lakes like data exploration and research capabilities. You may also adopt a data lake if you want to implement big data analytics for real-time fraud detection or personalization at scale.
About the author






