



Setting up a process to manage metadata (data about data) can address the triple threat of inaccurate messy data, slow access to information, and compliance risks. But only if done correctly. What you’re about to explore is seven key practices for effective metadata management. We’ll share practical advice, real-world examples, and expert tips you can apply immediately to improve how your company handles data.
1. Ensure these key elements are in place before launching a metadata management strategy
Metadata management will be a waste of resources—if you don’t have certain foundational data elements in place. These are a solid data infrastructure (including processes to collect, store, and analyze data) and a strong data governance foundation.
Why this is important: Without these basics, your metadata won’t accurately represent your data because it won’t have a consistent, reliable source of information to describe. It’s like trying to organize a library without knowing what books you have or where they’re kept.
Andrii Panchenko, lead of business intelligence (BI) and data management at Yalantis, highlights that metadata management can’t function in isolation:

Real-life example: US food manufacturer cooks up smooth data management processes
Yalantis’ data engineers helped a food manufacturing company with a complex supply chain avoid a recipe for disaster: an outdated data system where each department added ingredients to the pot in their own way. The result was a messy stew of duplicate and inconsistent information, difficult to process. Here’s how we helped them clean up their data kitchen our data engineering services:
- Implementing data governance—setting up rules for how data should be handled and used across the company. This includes creating data dictionaries, which provide metadata, and business glossaries, which offer business context. Together, they improve data literacy and enable cross-domain collaboration and insight-sharing.
- Assigning data owners—ensuring each department had someone responsible for overseeing their data’s accuracy and consistency.
- Updating data processes and storage—using Azure Data Factory to create new data pipelines and set up a central data warehouse on Amazon SQL Server. We also used Python to automate data loading and checking, which greatly reduced errors.
- Integrating metadata management—using AWS Glue to implement a metadata repository and data catalog to organize and describe their data assets, making them easier to find and use.
The result? A well-organized data kitchen where everyone could easily find what they needed, cook up insights faster, and serve up consistent, high-quality information across the board. A true chef’s kiss, as they say.


By getting these basics in place first, you can integrate metadata management tools directly into your data pipelines — which is crucial for solving common data challenges like inconsistent reporting, slow data retrieval, and compliance risks. See why this integration is essential next.
2. Integrate metadata management tools into your data pipelines to improve data quality, accessibility, and compliance
Automate processes that track key information about your data (like its source, format, and update history) as it moves through your systems. This approach is called active metadata management. It helps ensure data quality, makes information easier to find, and supports compliance by providing a clear record of data usage and changes.
Why this is important: With active metadata management, you create a self-updating inventory of your data, automating metadata updates. It helps you track data lineage—where data comes from, how it changes, and where it goes. This, in turn, helps identify data quality issues, logic gaps, and processing inefficiencies, solving several key business challenges.

Challenge #1. Inconsistent data prevents a unified view of business: Imagine a retail chain where the sales team enters customer names as “Last, First” while the support team uses “First Last.” This difference makes it hard to get a complete picture of customer interactions. Metadata management sets standard formats for everyone, so all departments use the same data language.
Challenge #2. Compliance risks threaten business reputation and finances: Regulations like the GDPR and CCPA require companies to handle data transparently, especially when it comes to sensitive data like customer information and financial transactions. With proper metadata management, you get a clear record of who accessed data, when, and why, making audits easier and ensuring compliance.
Example from Yalantis’ portfolio: When Yalantis set up metadata tracking for Oxygen, a FinTech company, it cut audit times from weeks to days by providing quick access to data handling records. This not only meets regulatory requirements but also builds trust with customers who care about data privacy.
Challenge #3: Delays in decision-making due to difficulty finding data: A marketing team might spend hours searching spreadsheets for last quarter’s campaign performance. With metadata management, they—and other teams—can quickly access the data they need to plan and optimize campaigns. Centralized repositories like Google BigQuery or Snowflake store this metadata, making it easy to find and use through BI visualizations or Alation catalogs.
Challenge #4. Poor data quality causes misinterpretations and errors: Companies often struggle to understand their data or its source. For instance, in manufacturing, ‘defect rate’ might mean different things to different teams—per item, batch, or production run. A good metadata strategy helps fix this by:
- encouraging teams to define data clearly
- promoting consistent terms across the company
- creating a standard “data dictionary” for everyone to use
This leads to better quality control and fewer misunderstandings. When everyone speaks the same data language, work gets easier and more accurate.
Metadata management tools in the center of a data pipeline: Examples, work principle, real-life cases
Active metadata management tools are software that help with tasks like capturing and storing information about your data, tracking where it comes from and how it changes. These tools connect raw data with the people who need to use it, providing context and control over how data is handled. Examples include AWS Glue Data Catalog, Informatica, and IBM Watson Knowledge Catalog. We’ll discuss how to choose the right tools in Best Practice 7.
As we show in the diagram below, active metadata management tools are central to the data pipeline. They influence how data is handled from when it first enters your system to when it’s used for analysis and reporting:
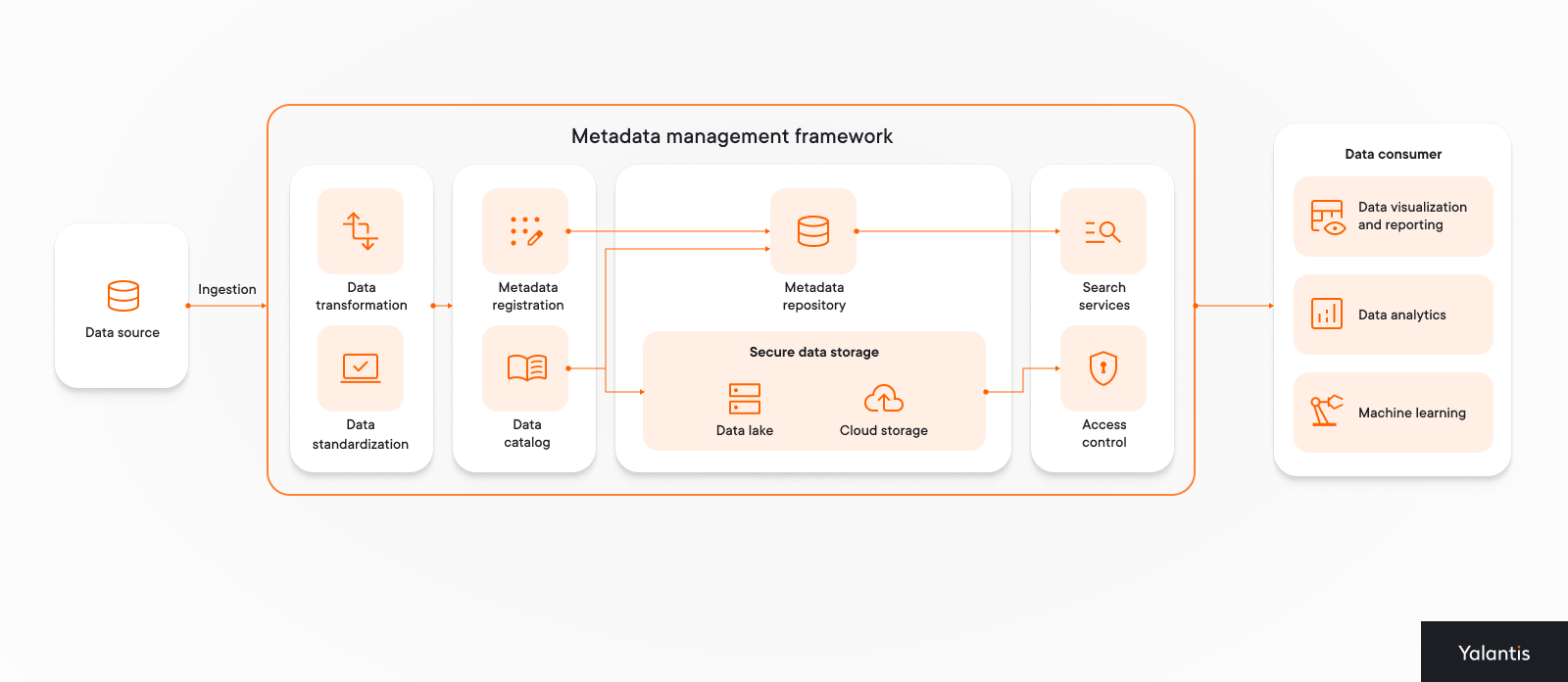
Without metadata management tools, different departments may use data inconsistently, resulting in disconnected information and unclear business metrics.
Real-life example: Dan Khasis, the CEO of route planning software company Route4Me, shared with us how metadata management solved their data fragmentation and inefficiency issues. By incorporating dbt (data build tool) into their data pipelines and using Alation and Collibra for metadata management, they dynamically manage metadata:

Integrating metadata management tools into your data pipelines is key for maintaining data quality, accessibility, and compliance. Leveraging data science services alongside metadata management can help automate and enhance data analysis, making it easier to extract valuable insights and improve decision-making. By analyzing metadata in conjunction with the data itself, you can uncover hidden patterns and optimize data workflows more effectively. But tailor the specific way you implement these tools to your company’s unique needs and industry—which brings us to our next best practice.
3. Customize metadata management strategy to your company’s specific needs and industry
Focus on your most urgent data challenges first—those that directly affect your bottom line or operational efficiency. A food manufacturer might prioritize standardizing data entry across departments, while a FinTech company could focus on tracking complex transaction data for compliance.
Why this is important: Attempting to solve all metadata challenges simultaneously often leads to resource dispersion, delayed results, and potential project failure.
Real-life examples from three industries: To show how customization works in practice, here are three examples where Yalantis helped clients adapt their metadata management strategies:
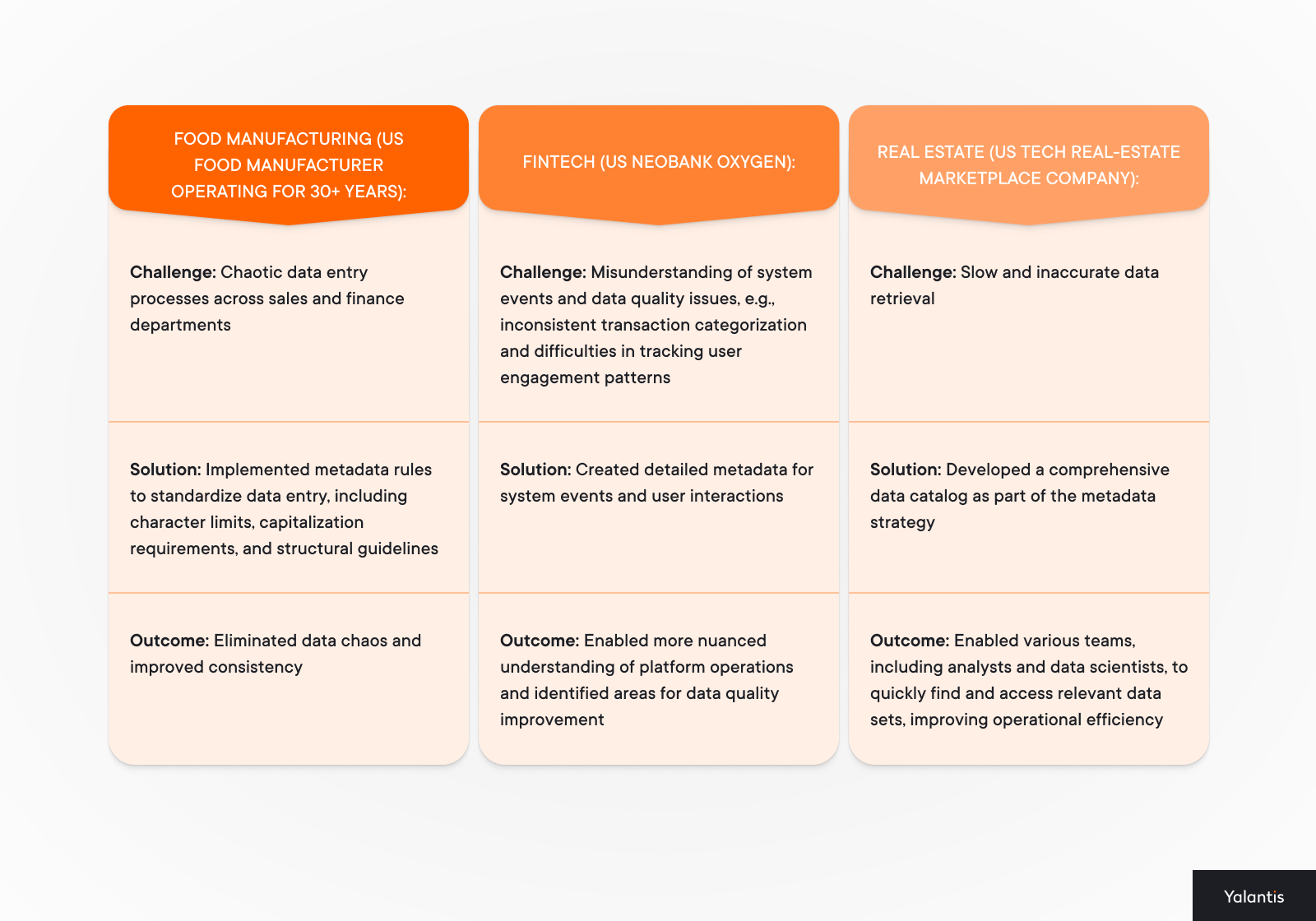


These companies didn’t waste resources chasing everything at once—they solved the most urgent challenges first.
Next, let’s see two essential components needed to establish a metadata management system.
4. Establish your metadata management system with a metadata repository and data catalog
To build a strong metadata management system, begin with a metadata repository and a data catalog. They form the core of your metadata infrastructure, enabling efficient storage, organization, and access to your metadata.
Why this is important: A robust repository and data catalog provide the foundation for effective metadata management. They allow you to centralize your metadata, make it easily accessible, and set the stage for more advanced practices as your organization’s needs evolve.
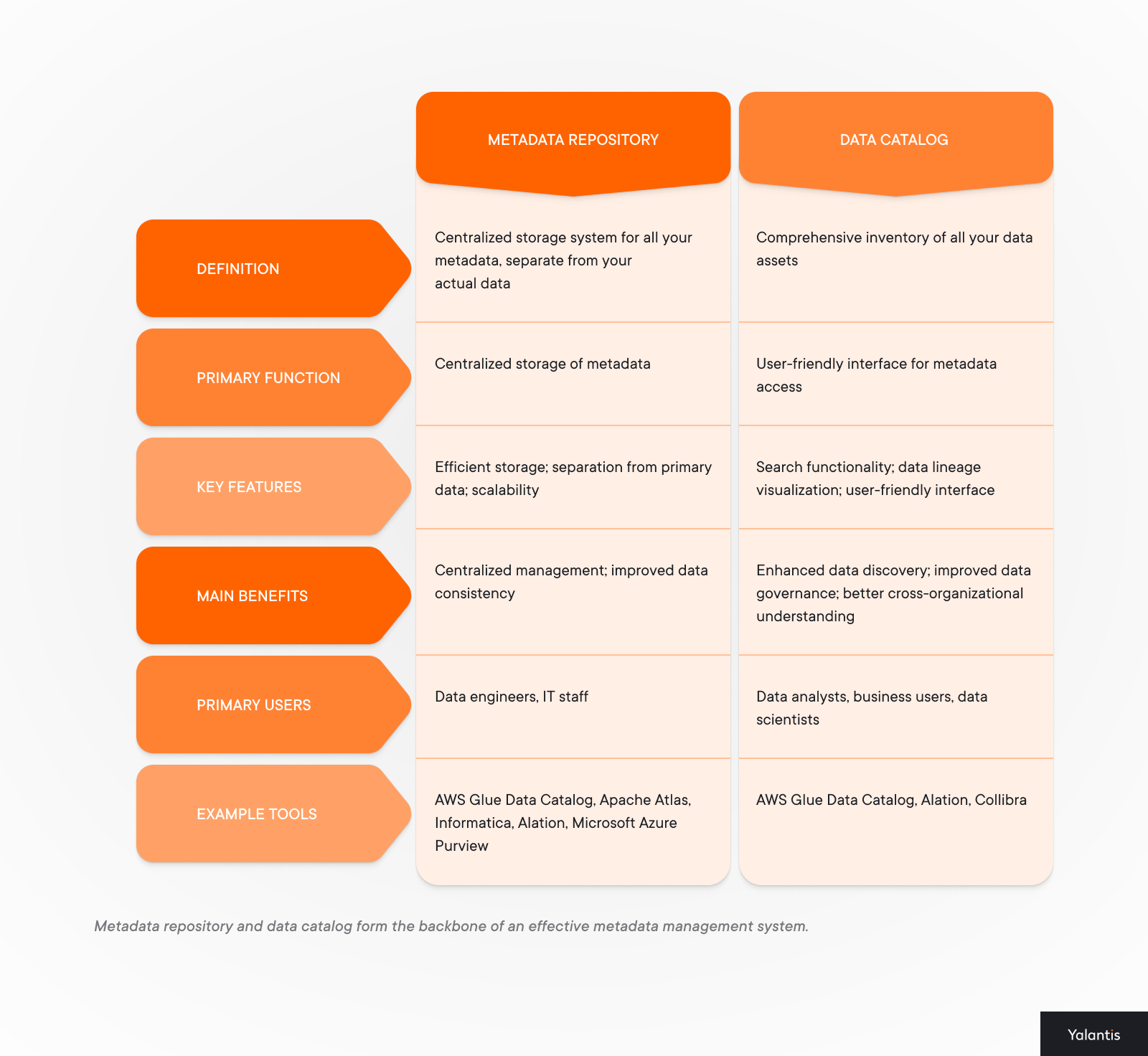
A metadata repository serves as a centralized storage system for all your metadata, separate from your actual data. This separation allows for:
- better organization and categorization of metadata
- efficient metadata management without impacting your primary data storage
- easier updates and maintenance of metadata independent of the data it describes
On the other hand, a data catalog is a centralized, constantly updated record of data origins, lineage, classification, and location. Integrated with a business glossary, it gives business users a clear, meaningful view of the data, which is essential for confident decision-making.
Ole-Olesen Bagneux, a noted data management expert, predicts that “data catalogs will evolve into company search engines, providing access to not only all the data but all the knowledge in your company.”
Metadata repository and data catalog working in tandem
The metadata repository and data catalog work together to provide a comprehensive metadata management solution:
- The repository stores and manages the metadata
- The catalog organizes and presents this metadata in a user-friendly format
- Together, they enable efficient metadata creation, storage, retrieval, and utilization
Real-life example: Yalantis data engineers often use AWS Glue Data Catalog as both a repository and a catalog. By integrating multiple data sources, they provide a clear view of data structures and relationships. Partnering with a data engineering company can help you implement similar solutions tailored to your data landscape, ensuring better visibility and streamlined data access across teams. This makes it easier for data scientists and analysts to find and understand datasets, speeding up analysis and decision-making.
As you build your metadata management system, it’s important to understand that not all data is “equal.” In the next section, we explore key distinctions between data, information, and knowledge in metadata management.
5. Understand the distinction between data, information, and knowledge in metadata management
Recognize and address the different levels of data maturity—data, information, and knowledge. Each one requires distinct management approaches within a metadata strategy.
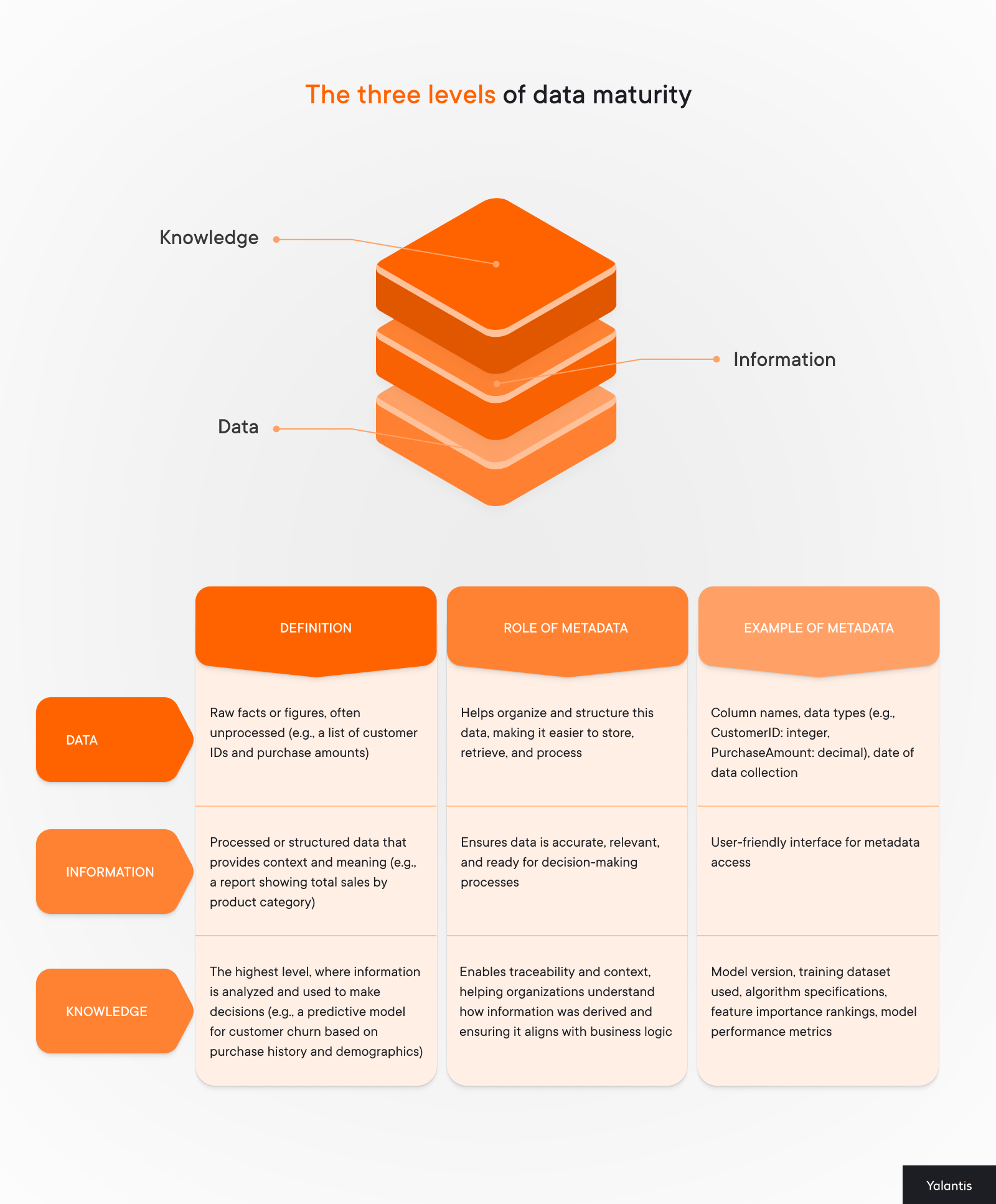
Why this is important: By tailoring your metadata strategy to the specific level—whether data, information, or knowledge—you ensure that your system supports the right business functions at the right time. For instance, Yalantis applied this distinction in various projects:
- Data management: A food manufacturer needed to organize raw data and eliminate duplication. We employed metadata to catalog and structure raw production and sales data.
- Information management: A real estate company needed fast access to relevant, structured data for decision-making. We used metadata to categorize and link various property and market data points.
- Knowledge management: A rapidly growing online bank needed to improve understanding of complex events and data-driven decisions. We used metadata to track the evolution of financial models and decision rationales.
How can you know to which specific level to tailor your metadata strategy? Identify whether your primary focus is on data collection, information processing, or knowledge creation.
Look at existing data practices, industry requirements, and future plans.
Let’s consider a hypothetical mid-sized retail company—an electronics retailer with both brick-and-mortar stores and an online presence. They’re looking to improve their data management practices. Here’s how they might evaluate their needs:
- Current state and goals:
a. Data maturity: Primarily at Data level with basic Information processing
b. Business goals: Implement omnichannel strategy and optimize inventory - Industry and data considerations:
a. Regulatory requirements: Accurate inventory tracking and financial reporting
b. Data complexity: Multiple stores, e-commerce platform, thousands of SKUs, seasonal inventory
c. Use cases: Frequent requests for inventory turnover reports by store and product category - Future plans:
a .Decision-making: Reliance on weekly sales and inventory reports for tactical and strategic decisions
b. Growth plans: Implementing predictive analytics for demand forecasting within the next year
Based on this analysis, they might focus their initial metadata strategy on solidifying their Data level management and expanding into Information level, while planning for future Knowledge level needs. Their strategy could include:
- implementing a data catalog for inventory and sales databases (Data level)
- developing standardized definitions for key retail metrics (Information level)
- documenting data lineage for inventory and sales reports (Information level)
- planning for future metadata needs related to customer segmentation and demand forecasting (Knowledge level)
This approach allows our electronic retailer to address their immediate needs in inventory management and sales reporting, while laying the groundwork for more advanced omnichannel and predictive analytics capabilities in the future. Leveraging data analytics services can further enhance their ability to extract valuable insights and optimize decision-making.
What do we have next? A strategy to ensure your metadata is comprehensible and useful to all stakeholders.
6. Enhance your metadata management strategy by combining it with documentation
Combine metadata management with up-to-date, comprehensive documentation to create a more complete and accessible knowledge base about your data. This combination improves decision-making by providing context and enhancing data interpretation across teams.
Why this is important: Metadata alone can lack the necessary business context for meaningful insights. Combining metadata with proper documentation (such as Confluence or Git) allows teams to grasp the full picture of data, its fields, and its usage. This combination:
- provides richer context for data interpretation
- offers guidance on data usage and interpretation
- explains the business logic behind data structures and relationships
For it to work, keep your documentation current. Outdated documentation, even if supported by metadata, can lead to manual errors and inefficiencies. To prevent this:
- Establish a regular review and update schedule for documentation
- Implement a change management process that includes updating documentation whenever data structures or processes change
- Use automated tools to flag discrepancies between metadata and documentation
Real-world example: A US food company we helped had outdated documentation, causing mix-ups and mistakes. We fixed this by:
- Updating all their data-related documentation
- Matching documentation with existing metadata with automated comparison tools
- Fixing differences by talking with data owners and business users
- Setting up automatic metadata updates to keep everything in sync
The results were that manual data entry errors dropped by 75%, data interpretation time decreased by 40%, and new team member onboarding time was cut in half.
Now that we’ve covered the human side of metadata management, let’s get to the non-human one. After all, it’s 2024—if we don’t bring up AI at least once, someone might revoke our “forward-thinking” badge.
7. Automate metadata discovery and optimization with AI and machine learning
Use AI and ML for enterprise metadata management to increase metadata accuracy and consistency, reduce manual work and errors, and solve data quality issues—especially helpful for companies with large, complex data environments.
Key use cases for AI and ML in managing metadata include:
- automated data discovery—finding and cataloging data across various systems without manual intervention.
- intelligent metadata tagging—accurately tagging metadata to improve data searchability and usability.
- identifying redundant data—spotting unnecessary data sources slowing down systems.
- proactive data lineage management—predicting and averting potential complications in data flows.
- predictive discrepancy detection—anticipating metadata inconsistencies before they occur.
- bottleneck prevention—identifying crucial data paths and predicting potential bottlenecks for preemptive action.
Real-world application: Dan Khasis, CEO of Route4Me, shares his company’s experience with AI and ML in metadata management:

AI/ML technologies reveal inefficiencies that humans might overlook. The key is to see them not as a replacement for human expertise, but as a tool that enhances our ability to manage and gain value from metadata. Partnering with a machine learning development company can further accelerate the implementation of AI/ML solutions, ensuring more effective metadata management and improving overall efficiency.
Now that we’ve explored how AI can help in metadata management, let’s turn our attention to the nuts and bolts of implementation. Up next: navigating the sometimes overwhelming world of metadata management software.
Selecting the right metadata management software for your data infrastructure
Selecting enterprise metadata management software that fits your current infrastructure can speed up implementation and increase user adoption. Here’s a simple guide based on our experience at Yalantis:
If you’re already using a specific cloud environment:
- Amazon Web Service users: Consider AWS Glue for its versatile catalog and data processing tools
- Microsoft Azure users: Look into Microsoft Purview for easy integration with other Microsoft tools
- Google Cloud users: Explore Google Cloud Data Catalog, especially if you’re using BigQuery
If you’re not tied to a specific cloud platform, versatile options include Collibra, Alation, Informatica, or IBM Information Steward.
Just starting out? AWS Glue or Google Cloud Data Catalog offer user-friendly metadata management solutions with low entry barriers, perfect for quick deployment and ease of use.
Remember — metadata infrastructure is a key component of your overall data architecture, not an isolated system. Treating it as an afterthought can lead to data inconsistencies, inefficient processes, and missed insights.
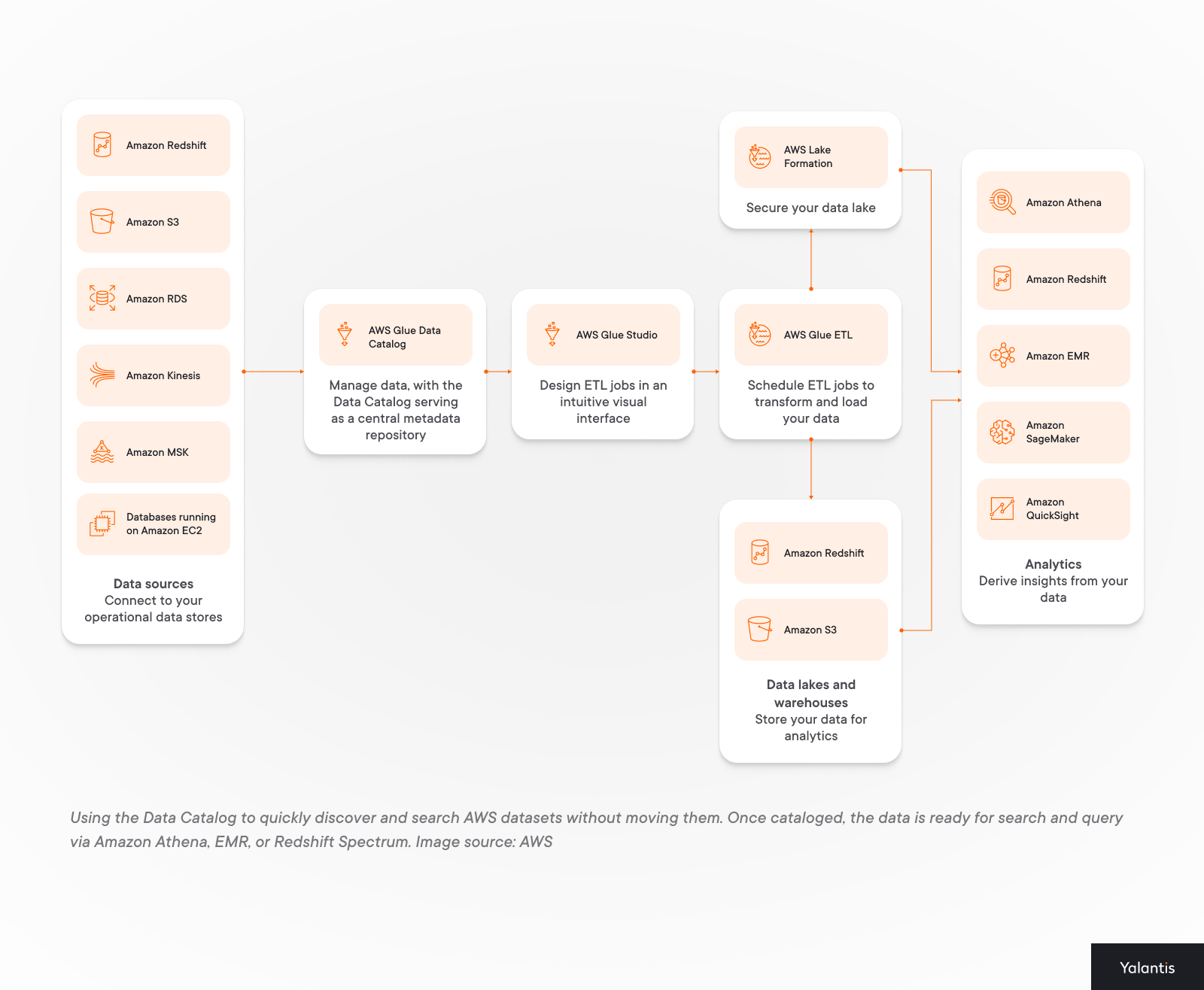
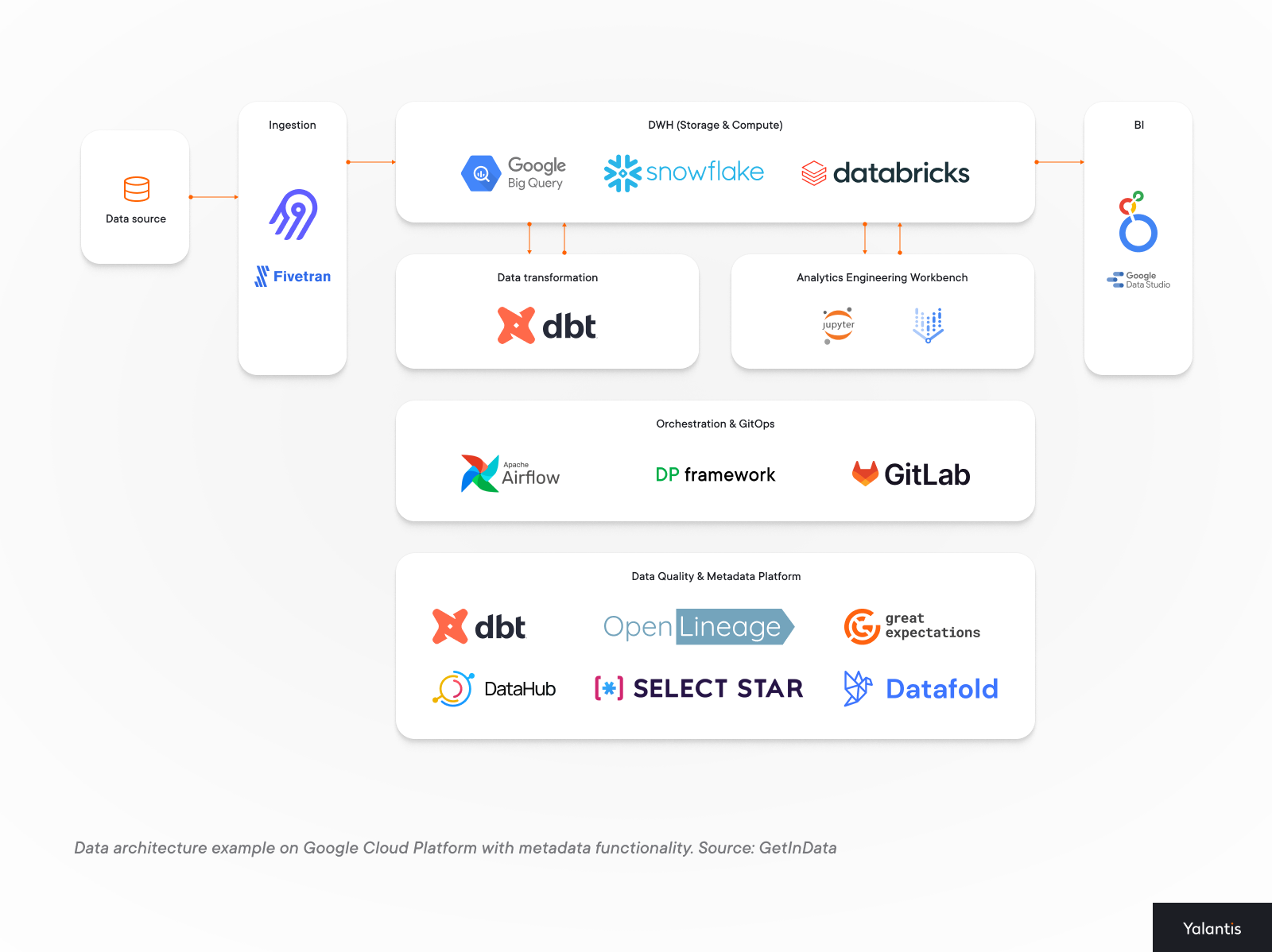
Here’s an example of how metadata functionality integrates into a Google Cloud Platform data architecture:


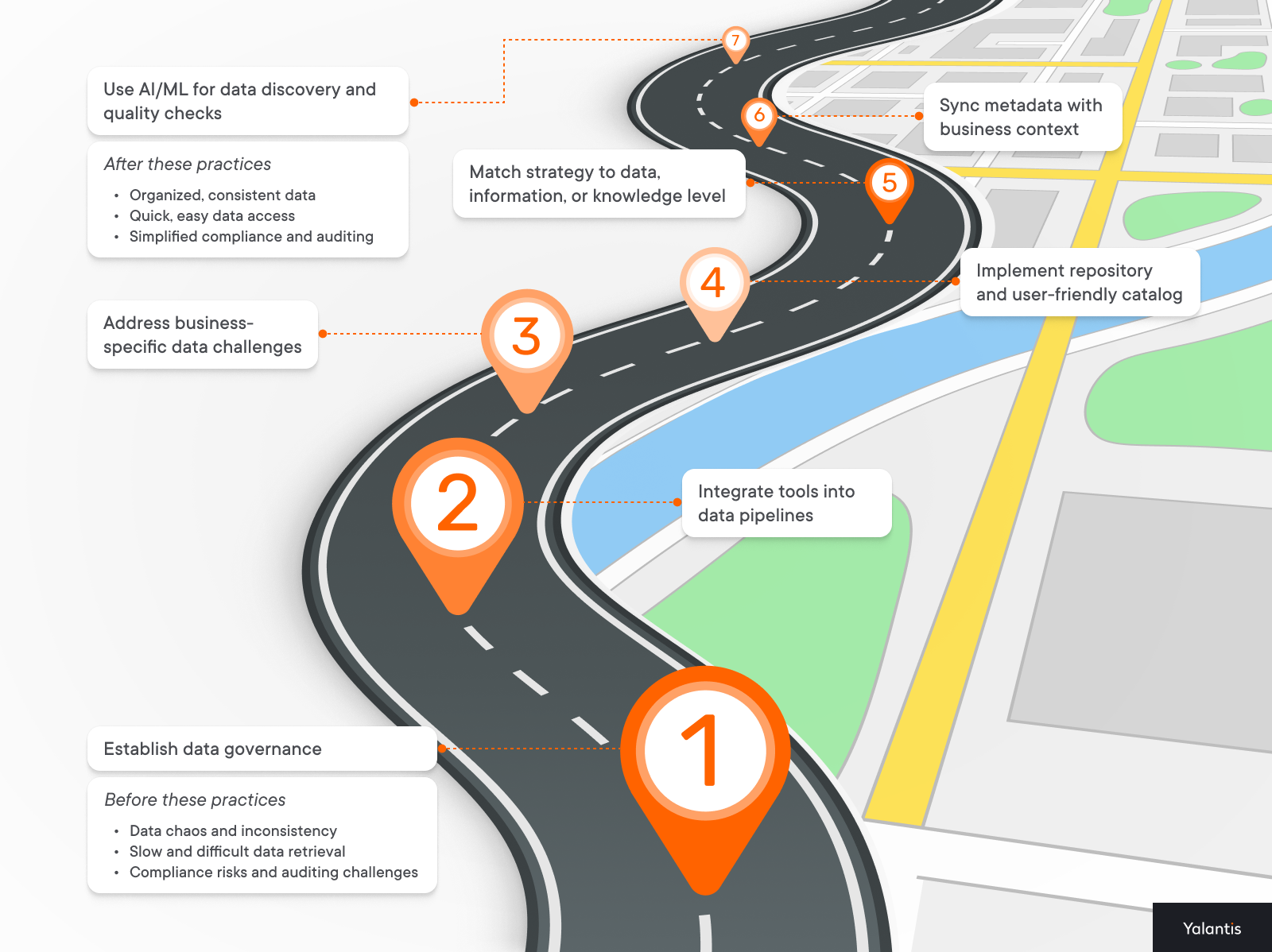
Mastering metadata management: Your 7-step roadmap
Good enterprise metadata management is like having a well-maintained GPS for your data highway — it keeps you on the right path, helps you avoid traffic jams, and ensures you efficiently reach your destination.
Before we wrap up, let’s review these seven strategies that form the backbone of effective metadata management:
Maximize the benefits of metadata management across your organization
By following these best practices, you’ll see real improvements in how your company uses its data:
- Make data easier to find and use: Help everyone in your company, not just IT experts, find and understand the data they need. This means faster, better decisions across all departments.
- Improve teamwork: When everyone understands what data means and where it comes from, teams work together more smoothly. No more confusion about conflicting reports or numbers.
- Save time, reduce errors, and improve compliance: Cut down on duplicate work and mistakes by clearly showing where data comes from and how it should be used. This means less time fixing errors, more time using data productively, and easier regulatory compliance.
- Understand your customers better: Connect the dots between different pieces of customer information to get a clearer picture of what they want and need.
Managing your metadata is an ongoing process. As your business evolves, keep updating your approach:
- Regularly review and update your metadata strategy (e.g., quarterly audits of your data catalog and lineage documentation)
- Adapt your practices to new data sources or business needs (for example, integrating metadata from a newly acquired company’s systems)
- Train new team members on your metadata processes to ensure consistent data management across the company
- Stay informed about new metadata management tools and technologies to continually improve your data governance and analytics capabilities
This way, you’ll always have the right information easily available that’ll smoothly guide your innovations—with less operational risks.


FAQ
What is metadata management?
Metadata management is the process of organizing, storing, and controlling metadata (data about data) to improve data quality, accessibility, and usability within an organization. One key type is technical metadata, such as the schema of a database table, which includes details like table name, column names, and data types.
What is the difference between metadata management and data governance?
Metadata management focuses specifically on handling metadata, while data governance is a broader framework that includes policies, procedures, and standards for managing all aspects of data within an organization. Metadata management is often a component of data governance.
Who is responsible for metadata management?
Typically, a data management team led by a Chief Data Officer (CDO) or Data Governance Manager is responsible. But it often involves collaboration across IT, business units, and data stewards.
What is the difference between metadata and MDM?
Metadata is information about data (e.g., definitions, origins, formats), while Master Data Management (MDM) is a method of linking all critical data to a common point of reference, ensuring consistency across an organization.
What are metadata management examples?
Examples include creating data catalogs, implementing data lineage tracking, standardizing data definitions across departments, and setting up metadata repositories.
What is the best metadata management tool?
Popular options include AWS Glue, Microsoft Azure Purview, Informatica, and Collibra, among others. The best tool is one that integrates well with your existing systems and meets your specific metadata management requirements.



