



Establishing a data lifecycle management (DLM) is a way to deliver relevant and high-quality data for analysis.
In the recent Salesforce survey among 10,000 IT leaders, 94% of respondents acknowledged that they need to derive more value from their datasets and improving data quality is on their top priority list. The right information at the right time drives business decision-making, fosters digital innovation, and gives businesses an advantage over competitors.
This article gives a detailed answer by discussing what DLM is, its core stages, and the benefits and challenges associated with an efficient DLM.
Achieve higher business process transparency with a custom DLM strategy
Explore our data quality management servicesWhat is data lifecycle management?
DLM is the process of managing, organizing, and securing data at different levels, from creation or collection to archival and deletion. This process gives you complete power over your data and allows you to track the entire data flow.
With the help of DLM, you can develop a structured approach to data management and optimize memory use by deleting data assets that are no longer needed. In addition, you’ll learn which datasets are important and which you lack for streamlined decision-making and incremental business expansion.
Why is DLM important in 2025?
DLM plays a crucial role in increasing the efficiency of business intelligence and data analytics implementations. Although BI professionals and data analysts can generate charts, tables, forecasts, and dashboards without DLM, the lack of a reliable lifecycle of data management can lead to problems with data quality, consistency, and relevance. In contrast, a well-integrated DLM strategy ensures that the data used in data analytics processes is accurate, reliable, and aligned with business goals, thereby maximizing the value derived from data analysis.
Business benefits of data lifecycle management
Establishing an end-to-end DLM strategy can help your business achieve the following benefits:
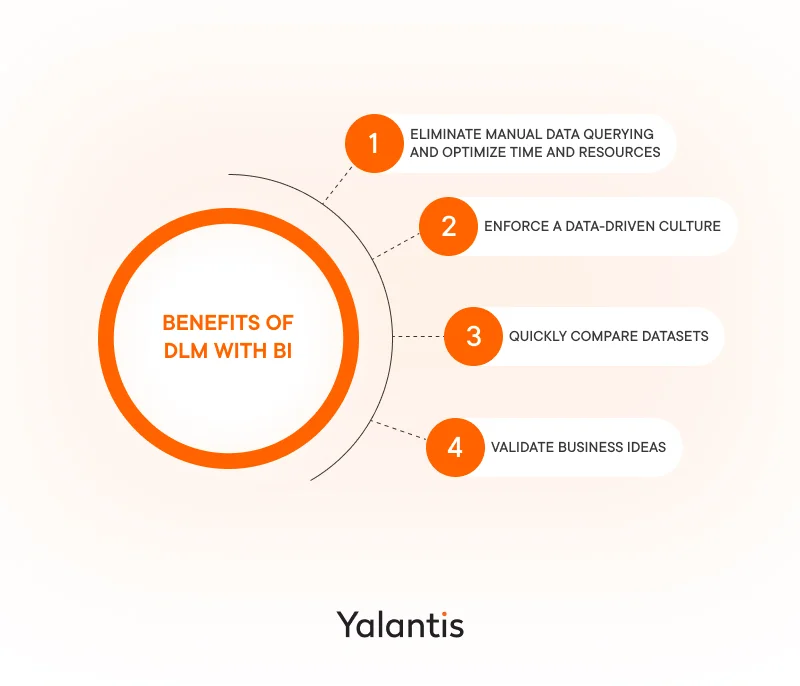
Eliminate manual data queries and optimize time and resources. A modern DLM strategy inadvertently involves the automation of certain processes, such as data collection and data processing. Automated data lifecycle management stages speed up data ingestion into data analytics tools, which can time-efficiently generate BI reports and dashboards and regularly show them to you, saving you, as a top manager, from hours of manually searching for the right information across departments and helping you optimize expenses.
Enforce a data-driven culture for different levels of decision-making. Adopting a data-driven approach to decision-making is an important step every business should take, even at its inception. When making decisions, there is a tendency to merely rely on the opinions of experts due to their experience and authority, but this isn’t effective if you strive to grow your business, generate revenue, and attract more customers. For instance, a C-level manager may have one vision of their product’s target audience, whereas a report can show a different perspective that could bring more revenue.
“Many companies do not pay enough attention to their data lifecycle and rely mostly on expert opinions in decision-making. This slows down business development due to the lack of a data-driven culture.”
Andrii Panchenko, Lead of BI & Data Management at Yalantis
Quickly compare datasets for a comprehensive analysis of your organization’s data effectiveness. Easily accessible high-quality data and BI solutions built on top of it allow for quickly decomposing all key business processes, validating their success, and defining issues or bottlenecks, such as by comparing budgets for two different projects and defining which is used more effectively.
Validate business ideas. As an evolving and ambitious business, you may often have ideas that need to be tested and validated before they’re implemented. Data that is properly collected and visualized in a convenient dashboard is exactly what you need in this case.
Possible use case: Your organization wants to test the performance of the referral program for your digital banking solution. In this situation, the data team:
- checks where and how data about referrals is collected and stored
- validates this data to define whether it’s sufficient and confirms that there are no fraudulent referral activities
These results can then be presented to you in a clear and transparent dashboard.


Key stages of the data lifecycle
Depending on your company’s unique business needs, the seven critical stages of the data life cycle listed below can involve different tools and steps.
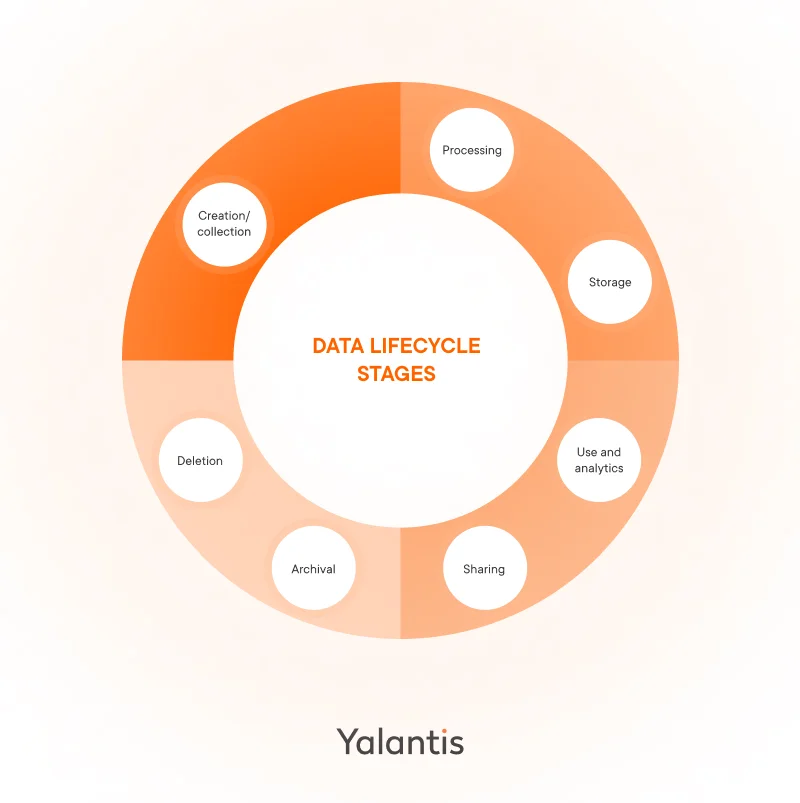
Stage 1. Data creation or collection
The first stage of the data lifecycle management process is collecting the raw data necessary to enable software development or set up specific business processes. At Yalantis, we’ve composed a few common rules for working with raw data:
- Establish solid communication between teams. Proper collection of raw data requires strong relationships between data and technology teams and other departments. These relationships allow data specialists to get to know owners of different datasets and collect data only after receiving the owner’s permission. Plus, with the help of data owners, data engineers can easily validate data sources and learn whether they contain quality datasets.
- Set requirements for receiving data. Data and BI engineers at Yalantis can dictate the characteristics that raw data should possess for a streamlined data collection process. These requirements vary depending on the business needs, but could be, for instance, a requirement for collecting unique data without duplication.
- Use a multi-tool approach to data management process steps. We prefer this approach, as it helps businesses stay flexible and smoothly collect data of different types from various sources. Depending on project requirements, we use Apache Kafka for real-time data streaming and Amazon Simple Storage Service (S3) to ingest data of different types into a data lake, and connectors to integrate with various databases. For instance, for our client Meroxa, Yalantis Go developers quickly built quality data connectors.
“I was most impressed with their team’s technical skills and the quality of their code. We compared their code with three other agencies, and theirs stood out; it was excellent.
Additionally, each connector was unique in that it required a lot of knowledge about the target resource it was being connected to. For example, writing a connector for PostgreSQL is drastically different than writing a connector for Stripe. They handled everything well when it came to understanding the more niche technical requirements, which really set them apart.”
Ali Hamidi, Co-Founder & CTO, Meroxa
- Optimization. It’s also critical to create unified approaches and templates for data extraction processes to save time on collecting raw data. This way, we can also simplify and accelerate the onboarding of new specialists to similar projects.
- Data accessibility. We request access to all critical data sources and datasets so we have all the data we need to move to the next DLM stage.
Stage 2. Data processing
At the data processing stage, the Yalantis data engineering team:
- investigates collected data to validate its quality and relevance
- cleans the data to ensure it’s consistent, includes critical values, and doesn’t contain inaccuracies or duplicates
- changes the data format if necessary to fit the data storage space
Our data engineering teams constantly keep in contact with the client during software development to ensure that we use only relevant datasets, as raw data can quickly lose its relevance. By staying in touch with the client, our team can also accurately define all data processes that align with business objectives to ensure that, during the data analytics stage, businesses generate only valuable insights.
Stage 3. Data storage
After data is collected and processed, the Yalantis data engineering team can ensure it is properly stored in the chosen data repository. For instance, this could be a database (Amazon Relational Database, Azure SQL, PostgreSQL), a data warehouse (Amazon Redshift), and a data lake (Amazon S3). The choice of data storage should depend on the systems you already use at your company, so that any new solution for storing data doesn’t disrupt your existing data management cycle.
Explore the difference between data storage systems
Read the articleStage 4. Data analytics
This is a stage when the BI team can use your data to derive insights and support decision-making. At this point, we can work with BI tools such as Tableau and Amazon QuickSight. Depending on your company and project maturity, we can implement advanced analytics based on machine learning (ML), such as predictive and prescriptive analytics, as part of our data science services.
“If a BI engineer also has data engineering skills, they can make smart and informed decisions about which datasets, metrics, and KPIs are relevant for visualization and analysis and how to shape the data processing algorithm to fit unique needs. This is what we at Yalantis consider to be the truly intelligent part of BI.
By combining skills from different areas, a specialist can not only work according to the technical specifications but also be creative in solving problems, offer optimal solutions for the business, and establish the right approaches to data processing.”
Andrii Panchenko, Lead of BI & Data Management at Yalantis
Stage 5. Data sharing
To ensure your data isn’t compromised, a strict data security policy and data protection controls should be established. For instance, at Yalantis, we encrypt data at each stage of the data lifecycle and comply with role-based access controls to ensure that only authorized users can access data.
Data sharing processes can be internal and external, and it’s crucial to secure both. For instance, a data minimization technique can ensure that users, applications, or third parties get only those datasets that are critical for them. Data anonymization is another way to protect your data from breaches or malicious attacks, as it helps to obscure your datasets during sharing. Depending on the business requirements, we can establish a unique data sharing system that protects your data during all phases.
Stage 6. Data archival
Data owners decide which datasets are no longer relevant and can be archived. However, it’s also important to keep archived data available and accessible for future reference, historical analysis, and compliance. The tricky part lies in choosing the right tools and storage solutions to ensure easy access to archived data, without cloud or on-premises storage costs soaring.
If a certain dataset is used across multiple departments, then it’s critical to define the period of use for each department and make sure no one will need it before archiving. Plus, timely identifying archived datasets that need to be deleted is also important, as you may continue to pay for data storage that’s no longer serving any purpose.
Stage 7. Data deletion
This is the final stage of the data lifecycle, which involves deleting datasets and freeing system and server capacity for other data that can be of more importance to the business.
Implementing and maintaining data classification tools simplifies data deletion, as they allow for classifying your data according to sensitivity, compliance, and business value. Based on this categorization, you can build a custom data retention regulations that can help you easily define which datasets and when should be deleted or archived.
As a data management services provider, we believe that properly setting up data lifecycle management has a strong influence on business efficiency.


But to achieve efficient data lifecycle management, it’s critical to start by establishing metadata management that facilitates the creation, retrieval, storage, and sharing only of contextually rich datasets.
Metadata management as a part of DLM
Metadata, or data about your data, provides valuable context on when data was created or updated, who created it, and how it relates to other data. Without this context, you risk groping in the dark when trying to derive meaning and, most importantly, business value from your datasets.
Metadata can have an even longer lifecycle than your data. For example, you might delete a dataset but keep its metadata to document decisions or track how your systems evolved. You might also create metadata in advance to outline what a future dataset will include, especially when planning ahead. Either way, managing metadata gives your team a clear map of what’s going on across systems, timelines, and departments.
Establishing metadata management practices allows you to ensure efficient data integration, avoid data quality issues, and improve data accessibility and traceability. Below are four essential stages of metadata management, which can help you begin your data lifecycle management in the right place.
Metadata capture. Defining which fields your metadata should contain is the first step before capturing relevant metadata. Overwhelming your data with too much metadata breeds confusion and only complicates data retrieval, storage, and subsequent analysis. And if your data lacks essential metadata fields, it can also create issues with understanding the data. A common number of metadata fields is from 6 to 15, such as key dates, creator name, and usage rights.
The most effective way to define which fields to capture is by analyzing the value each of them can offer your business. For instance, if you’re working on a logistics dashboard, capturing the timestamp of each delivery can help calculate delivery delays and optimize route planning. Metadata fields form a metadata schema, which in turn is the core for building a comprehensive metadata repository.
Metadata storage. Implementing a centralized metadata repository, such as AWS Glue Data Catalog, allows organizations to securely store and track their metadata to quickly retrieve it. Keeping metadata safe and separate from primary data in a consolidated repository streamlines data management, especially for large datasets.
Explore how to create efficient data models that simplify data architecture design.
Read the articleMetadata organization. Cataloging and organizing metadata in the repository is another step to building an efficient metadata management system. With a well-structured metadata catalog, you can easily locate and use metadata. Metadata can be organized manually, automatically, or semi-automatically. It’s also at this stage that you can define the duration of your metadata lifecycle.
Metadata governance. Metadata management is often a part of a larger data governance framework, which defines who is responsible for managing, owning, updating, and organizing a metadata repository.
With a fully set-up metadata management and metadata lifecycle, you can have more context to establish clear rules for data lifecycle management.
DLM and regulatory compliance
From the moment data is collected to the point it’s deleted, organizations are expected to handle it according to the legal and industry-specific requirements that apply to their operations. Standards like HIPAA, GDPR, PCI DSS, CCPA, and ISO 27001 all emphasize not just protecting data, but understanding data lifecycle management, from start to finish. Below is how each DLM stage ties into regulatory obligations:
Data creation or collection. Compliance starts with collecting only what’s necessary and doing it transparently. GDPR and CCPA require consent and clear communication on data usage. HIPAA limits what patient data can be gathered, and PCI DSS requires secure methods for collecting payment data. We work closely with data owners, validate sources, and apply strict requirements to ensure data is relevant, clean, and legally collected.
Data processing. At this stage, we ensure that data is processed only for its intended purpose. GDPR requires lawful and minimal processing. HIPAA and ISO 27001 call for access control and data protection during transformation. We use tools like Apache Airflow and Spark to orchestrate workflows securely and validate data quality before it moves forward.
Data storage. Storage must balance security and accessibility. HIPAA and ISO 27001 require encryption and access logging. PCI DSS enforces secure storage of cardholder data. We use encrypted cloud storage like Amazon S3 or Amazon Redshift, applying strict role-based permissions and regular audits to protect data at rest.
Data analytics. GDPR limits data use in profiling or decision-making without proper justification. HIPAA requires de-identification of health data in analytics. We ensure that only relevant, approved data is analyzed, and that sensitive information is masked or anonymized when necessary.
Data sharing. Sharing is where compliance often breaks down. GDPR and CCPA require clear disclosures on who gets access. PCI DSS and ISO 27001 enforce secure transmission. We limit data exposure through encryption, access controls, and minimization, so only necessary information is ever shared.
Data archival. Just as active data, inactive data should be regulated too. HIPAA requires long-term retention, GDPR requires justification, and ISO 27001 advises regular reviews. We archive data securely with predefined retention periods and ensure it remains accessible for audits, but not stored longer than needed.
Data deletion. At the end of the lifecycle, data must be securely removed. GDPR grants the right for on-demand data deletion. PCI DSS and HIPAA require secure deletion methods. We use strong categorization to guide retention policies and deletion schedules, ensuring that data is wiped clean when no longer required.
Embedding compliance into every DLM stage protects your data, reduces risk, and builds long-term trust. At Yalantis, we consider compliance a guiding principle in everything we do with data. We also follow a set of data lifecycle management practices, established based on our time-tested approach to efficient data management.
Best practices for implementing DLM in 2025
Here are a few best practices for succeeding in DLM implementation from Yalantis’ data architects and data engineers:
- Analyze current DLM practices. Analysis is necessary to define possible issues with your data lifecycle and come up with an improvement plan.
- Create a full-blown data ecosystem. This means thinking through every detail of the data lifecycle and developing a clear schema showcasing how data is collected to how it gets archived or deleted.
- Continuously maintain each DLM stage. Our data engineers not only set up DLM processes but also constantly ensure they function as needed and make updates or changes when necessary or requested by the business.
- Compare data management and analytics tools and perform advanced competitor research. We aim to ensure you’re ahead of the game in your industry. When selecting data tools, we take into account not only your needs and resources but also what your competitors use.
- Develop a DLM implementation roadmap. To ensure smooth implementation that won’t disrupt your business workflow, our data team develops a detailed plan tailored to your business needs, industry and regulatory requirements, and organizational structure.
- Integrate advanced analytics and data science capabilities. If you want to derive value from such solutions as predictive analytics, machine learning models, generative AI algorithms, and chatbots, we can help you with their integration, maintenance, and troubleshooting. Explore our ML development services to learn how we design, implement, and support tailored machine learning solutions for various industries.
- Onboard and train employees. We can conduct regular knowledge-sharing sessions with your in-house team and our experts to prepare detailed training materials and documentation to help you streamline user onboarding to new solutions.
Efficient data analytics and business intelligence go hand in hand with data lifecycle management in a modern, mature, and growing organization. You shouldn’t rush into data analytics and deriving business insights from your raw data without first properly organizing your data lifecycle. If a business lacks a unified data collection and data monitoring flow, doesn’t know precise data owners, or is missing a data processing stage altogether, their BI initiatives will most certainly fail.
The role of composing a skilled DLM management team
The people involved in organizing the DLM flow can vary depending on the project you’re working on and your evolving business requirements. But such roles as CDO and data architects are critical to ensure that DLM is woven into your entire organization.
A CDO is responsible for orchestrating the DLM process, assigning other critical roles for this process to run smoothly, and reporting to other C-level executives on the data condition and data analytics capabilities. The data architect builds data architectures that align the organization-wide DLM strategy with the company’s business goals, taking into account functional and non-functional requirements that digital systems should have. Working closely with data engineers and BI specialists is also critical.
“A data engineer at Yalantis is responsible for data mechanics and fine-tuning how data is collected, stored, used, shared, archived, and deleted. Whereas a BI engineer is responsible for looking for data owners, differentiating between metrics, assessing the way data is structured, and defining which data is necessary for generating insights and visualization. We’re often looking for specialists who can do both data engineering and business intelligence.”
Andrii Panchenko, Lead of BI & Data Management at Yalantis
Selecting suitable technologies is another crucial aspect of building an efficient data lifecycle management flow. In the next section, we cover a few common options, which can differ depending on the business cases.
Tools and solutions for data lifecycle management
For metadata and cataloging, we often use AWS Glue Data Catalog or Apache Atlas. They’re reliable, well-integrated with modern data stacks, and make it easier to track where your data comes from and how it changes over time.
To enable efficient data processing, we use Apache Airflow, Apache Spark, or Tableau Prep. Apache Airflow helps in orchestrating complex data workflows and optimizing extract, transform, and load (ETL) processes. The latter can be managed and monitored as directed acyclic graphs (DAGs). Apache Spark is best suited for large-scale and real-time data processing. Tableau Prep is useful for effective data processing if a business uses Tableau as a BI visualization tool.
When it comes to governance and compliance, platforms like Collibra and Informatica do the heavy lifting. They let you set up and enforce retention rules, manage access, and stay in line with GDPR, HIPAA, and whatever else applies, without slowing down your team’s workflow.
Cloud platforms like AWS, Azure, and Google Cloud also now offer native support for DLM tasks. You can automatically move cold data to cheaper storage or delete it after a certain period, without any extra setup. That kind of automation saves time and helps avoid unnecessary storage costs.
These tools don’t solve everything, but they take the pressure off. With the right setup, you can stop worrying about missed compliance deadlines or outdated datasets clogging your system and focus on what your data is telling you.
Common DLM challenges and how to overcome them
Thinking through your company’s DLM flow in detail is beneficial in many ways and helps you avoid the following pitfalls:

- Increased costs for storing irrelevant or duplicated datasets. Even though digitization initiatives enable businesses to generate large amounts of data every day, companies may store datasets that are either unnecessary or too outdated to bring any value. This results in increased costs for data storage and maintenance. With a well-thought-out DLM strategy that fits your business model, you can get rid of these datasets and store more relevant data instead.
- Insecure data sharing within and outside the company premises. With a regulated data flow, you can ensure that data is securely exchanged within and outside your company. Using structured and governed data across BI services helps maintain consistency in reports and insights shared between teams. At Yalantis, we follow a security-by-design approach to the data lifecycle, which begins with a properly established system of access and permissions to sensitive data at the data collection stage and continues with setting up robust security controls during the following stages.
- Accidental loss of business-critical data. If you’re aware of how and where your business data is stored and organized, you can be more confident that it won’t accidentally get lost or misused to harm your reputation.
- Data analysis with poor-quality data. If you begin data analytics with insufficient datasets that, for instance, are missing crucial values, this can lead to ambiguous insights and affect decision-making. As part of your data lifecycle management framework, you can implement data processing practices that ensure only data of sufficient quality moves further in the DLM funnel.
“BI and data have a tremendous impact on business decision-making in different aspects. And it’s better to show nothing than to show a badly prepared BI report or dashboard that can lead to a wrong decision-making path.”
Andrii Panchenko, Lead of BI & Data Management at Yalantis
- Data silos that make it difficult to retrieve critical data. Developing a unified approach to data collection within your organization can help you avoid the constant struggle of retrieving data from multiple siloed data sources.
How Yalantis can help you streamline DLM
In the context of a data-driven culture and business decision-making, we consider important aspects such as security, velocity, quality, and accessibility of data, as only after fine-tuning all of these aspects is it possible to generate valuable insights.
“BI and data connect the entire company infrastructure, and the aim of BI projects is the implementation of data processes using diverse resources such as cloud solutions, standardization, and documentation, focusing not only on the end result which the user will see in the form of a report or dashboard but also on how the data lives.”
Andrii Panchenko, Lead of BI & Data Management at Yalantis
For Yalantis, effective data visualization and business intelligence are the consequence of well-set-up data lifecycle management processes, and we often combine data engineering and BI capabilities to help businesses generate rich and high-quality insights. What BI and data stand for at Yalantis:
We’ve been providing data engineering and data lifecycle management services for a wide variety of businesses across industries, including FinTech, healthcare, logistics, real estate, and manufacturing. For instance, we’ve helped a US-based neobank efficiently define fraudulent activities and generate deep-dive insights about customer behavior to improve and personalize their experience. As a result of our cooperation, we helped the company:
- decrease fraud-related financial losses by 40%
- achieve a 5% increase in the user adoption rate
To become a data-driven organization with reports and dashboards that simplify and enrich your decision-making, you should consider paying due attention to each stage of the data lifecycle. By implemeting the right technologies, establishing regulatory compliance, thinking through metadata requirements, your data lifecycle can work for your business, forming efficient data pipelines that ingest quality data to the quality data analytics tools, which generate quality and impactful reports. Data lifecycle management is a strategic initiative that can make or break business decision-making, depending on how well-structured it is.
Modernize your business processes by nurturing a data-driven environment
Partner with Yalantis to integrate custom data analytics tools that drive decision-making
FAQ
Is DLM relevant only for large enterprises?
Large enterprises might deal with more dire consequences of poor data management lifecycle, as they have lots of scattered and siloed datasets. Therefore, it can seem that DLM is a must-have for them to survive a growing data chaos. However, mid-sized and small companies can also benefit from DLM adoption. If you’re collecting data, using it to make decisions, and need to stay compliant, DLM helps you avoid chaos before your company becomes an enterprise, cut storage costs, and build scalable processes from the start.
How can AI and automation improve DLM processes?
AI and automation can take a lot of the manual effort out of managing data. For example, data automation tools can classify data based on usage or sensitivity, archive files that haven’t been touched in months, or even flag anomalies in data retention. AI can go a step further by recommending retention policies based on usage trends, identifying risky access patterns, or helping classify unstructured data more accurately. This saves time and reduces human error, especially at scale.
What are the risks of poor data lifecycle management?
The possible risks include compliance issues, data breaches, increasing data storage costs, and inefficient decisions made on outdated or low-quality data. Without clear data lifecycle policies, certain data might hang around longer than it should, or critical business data might get deleted too early.
What are the common challenges companies face with DLM?
One of the biggest challenges is understanding where all your data is and who owns it. Beyond that, companies often struggle with inconsistent metadata, fragmented systems, unclear retention rules, and low stakeholder engagement. It also takes effort to balance strict compliance needs with the flexibility that teams often want when working with data.
How do I start implementing a data lifecycle management strategy?
Start by increasing visibility of your current datasets: what data you have, where it lives, how it’s used, and who owns it. From there, define a few basic policies: how long it takes to keep different data types, how to archive or delete it, and who is responsible for each stage. It doesn’t have to be perfect from day one. Start small, document your process, and build from there as your data maturity grows.
What is the difference between data lifecycle management and data governance?
DLM is about what happens to your data over time, from creation to deletion. The Data lifecycle consists of seven crucial stages that impact each other. Data governance is the broader framework that defines how data is handled across the organization, including policies, roles, responsibilities, and quality standards. Think of governance as the rulebook and DLM as the play-by-play. One supports the other, and they work best when aligned.
About the author






