


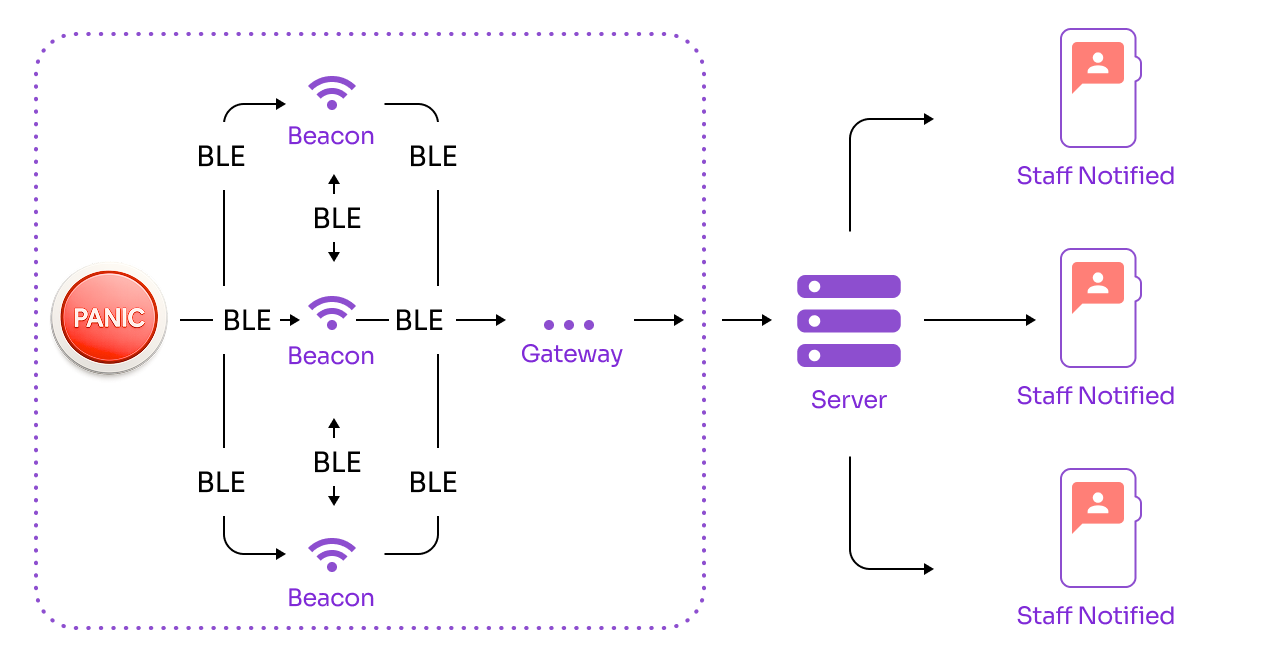




Stabilize and scale the emergency button system.

Emergency Panic Button System Migration and Cloud Cost Optimization for ROAR
ROAR develops SOS buttons for employees in hospitals and hotels worldwide. They needed a tech partner to help them cut cloud costs, improve device connectivity, and speed up releases.
60%
Cloud expense reduction
3x
Device connectivity improvement
8x
Faster deployment time






“ROAR came to us to migrate their gateways to the new connectivity system. But more broadly, they needed a partner to help them reduce costs and grow.”
– Mykhailo Maidan, CTO at Yalantis
Need to build an AIoT platform from scratch? Let’s make it happen.
How ROAR upgraded 80K devices and cut cloud costs by more than half
In just 6 months, ROAR migrated all gateways to a new emergency medical alarm system, redesigned the architecture for 60% cloud cost optimization, and implemented best development practices with Yalantis’ support.
How we solved the client’s challenges
Migrated 2500 gateways from NervesHub 1.3 to 2.2 in 2 months
Redesigned infrastructure with AWS IoT Core and cut cloud costs by 60%
Improve device connectivity. Reduce high cloud infrastructure costs.
Introduced isolated environments for faster deployments
Speed up deployment and updates.
Reduced update deployment time from 2 h to 15 min
Guide the team on best DevOps practices.
Provided CTO support, team training, and ongoing guidance
Continue evolving the platform.
Enabled reliable event processing with AWS Lambda and Amazon Kinesis
Handle spikes of real-time device events efficiently
Connectivity improved from 20% to 80%
Migration to NervesHub 2.2 ensured gateways connected consistently, reducing failed connections threefold.
60% AWS cloud costs cut
By redesigning AWS infrastructure, we reduced operational expenses by more than half without affecting performance.
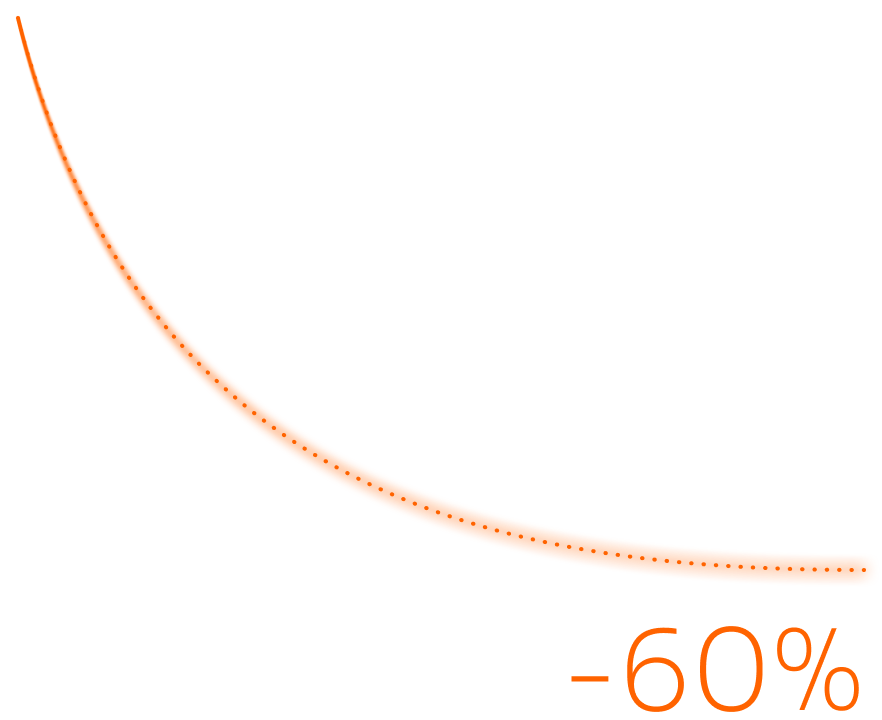
Deployment time cut from 2h to 15 min
New development practices and streamlined workflows allowed the team to release updates 8 times faster.




Discover the key milestones of our partnership
Fulfil your success story with us. Share details about your project and book a call with us to discuss your goals.




From medical devices to industrial automation — we deliver complete enterprise solutions with regulatory compliance built-in. Everything under one roof.
Our offices

Poland
123 al. Jerozolimskie, Warsaw, 00-001

Ukraine
5 Dmytra Yavornytskoho Avenue, Dnipro, 49005

Cyprus
8 Athinon Street, Larnaca, 6023

Estonia
12 Parda, Tallinn, 10151

FAQ
-
How did you handle the firmware platform migration without risking emergency call button app availability?
Our team rolled updates in waves, tested multiple emergency scenarios, and auto-validated update success to catch failures immediately. This approach kept emergency panic button app reliable while delivering a large-scale OTA upgrade.
-
What exactly drove the 60% cloud cost reduction?
Our team re-architected the AWS stack for elastic scaling, optimized data storage with tiered approaches, reduced redundant logging/traffic, and added autoscaling rules so capacity matched real load. The end-result was lower spending without sacrificing performance or flexibility across resources, options, and budget planning.
-
What scale can this architecture support, and what changed in reliability?
The platform processes data from ~80,000 devices (status, alerts, logs) and, post-work, supports more devices at lower cost. Connectivity improved substantially (reported as moving from 20% to 80% after migration and hardening), with better management of resources and features.
-
How did you achieve the 8X faster releases in practice?
We introduced isolated environments, CI/CD automation, stronger documentation and testing, and a cleaner release flow, cutting deployment time from ~2 hours to ~15 minutes.
-
If we engaged you, what team and engagement model should we expect after go-live?
The core team included a PM, CTO, backend engineer, and DevOps across IoT consulting and product development, with ongoing architecture reviews, cost management, and best-practice guidance beyond initial optimization. Engagement remains transparent around budgeting and ongoing customer success.
-
What did you tackle to stabilize the system and de-risk operations?
Days 1–30: restore observability and safety, add monitoring/alerts, introduce canary OTA with instant rollback, and fix the noisiest connectivity paths.
Days 31–60: run a staged migration of ~2,500 gateways from NervesHub 1.3→2.2 in controlled waves with auto-validation of failures to protect emergency availability.
Days 61–90: re-architect AWS for autoscaling and lean storage/traffic, and stand up CI/CD, raising connectivity from ~20%→~80%, trimming cloud spend ~60%, and cutting release time from ~2h to ~15 min (~8× faster).
Let’s Start from call scheduling
- Schedule a call
- We collect your requirements
- We offer a solution
- We succeed together!
Welcome to Yalantis, please fill up the form and we’ll get back

Thank you for contacting us.
Keep an eye on your inbox. We’ll be in touch shortly
Meanwhile, you can explore our hottest case studies and read
client feedback on Clutch.
Meanwhile, you can explore our hottest case studies and read
client feedback on Clutch.
We are open for partnerships too
Check out our refferal program. Find out all benefits.