Finding a competent technical vendor who can solve your business challenges is only half the battle. The other half is making sure your partner employs healthy development practices that we talk about in this article.
When you contact a potential technical partner, you should make sure they have a streamlined process and guarantee the continuity and stability of development.
In this article, we introduce our approach to developing technical solutions for your business challenges.
What does our app development process look like?
We’ve combined thirteen years of experience in app development with time-tested development methodologies to create a new Agile approach. In addition to offering visibility, this approach makes development predictable and easy to manage.
According to our approach, we first select one of three software development lifecycle (SDLC) frameworks we’ll talk about later and then adjust it to the project based on the type of company and your business needs. SDLC is a term used in the software development industry for a framework that defines tasks performed at each step of the software development process.
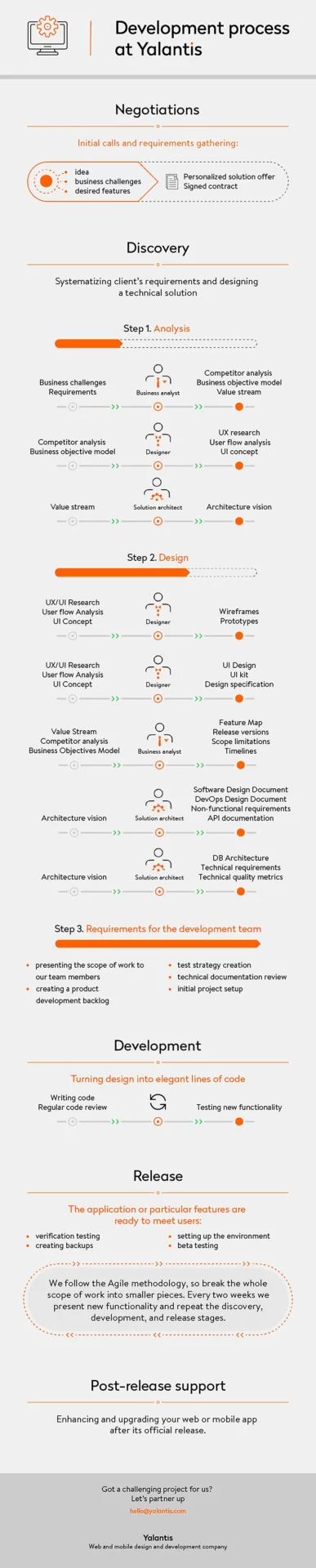
Negotiation phase
This is the initial phase that precedes the start of the project.
We care about the intellectual property of our clients, so we’ll send you an NDA right after you contact us and will sign it before we start negotiations.
During this phase, we hold several calls with you and gather the information that will help us choose the right technology stack, team structure, and technology solution for your specific business challenge. We also define possible risks that can slow down development or cause issues and search for ways to eliminate them.
On the basis of this information, we create a personalized offer. This offer contains all information about your project, including the tech stack and team structure. Upon your request, we’ll also make a rough estimate of the project. These deliverables will help you understand how we’ll solve your specific business challenges and how much time and money you’ll need to build your product. After that, we sign a contract. Our SDLC starts after signing all required documents.
Read also: How can you find and hire the best app developers
Discovery phase
The first phase of the SDLC is discovery. This phase consists of several stages:
- Analysis
Our business analyst conducts a detailed analysis of your company and business niche. They gather business requirements, conduct market and competitor analysis, and define end users.
After that, the business analyst creates a value stream: a selection of actions that create additional value for the client beyond the initial request. The business analyst also creates a Business Objective Model (BOM) to document the project’s value. These deliverables are the grounds for further research by our solution architect and UI/UX designer. During this phase, we also collaborate with our data science services team to analyze available data and ensure the technical solutions we propose are aligned with your business needs and can leverage data-driven insights for better decision-making.
On the basis of this information, our solution architect analyzes the project architecture and searches for the best technical solutions to solve your business problem. As a result, they come up with an architectural vision for the product.
At the same time, our UI/UX designer creates the first drafts of the product’s design. Having discussed the look and feel of the product with you, the designer conducts UI and UX research, creates UI concepts, and picks a color palette.
Read also: What Role a Business Analyst Plays in Yalantis
- Design
Our business analyst prepares a design backlog, functional requirements (what the product must do), nonfunctional requirements (reliability, usability, performance, etc.), and a document called the product roadmap outlining the direction and progress of product development. After getting the design backlog, our designers start to turn your expectations into a beautiful user-friendly design. They create wireframes that show how different elements (buttons, menus, etc.) are placed on the screen. When wireframes are ready, it’s time to breathe life into them by designing the product.
Meanwhile, our solution architect creates a Software Design Document (SDD). This document contains API documentation, database architecture, technical requirements, nonfunctional requirements (platform restrictions, technology stack, infrastructure architecture, etc.), and quality metrics. After all the requirements are gathered, our security team conducts an acceptance test to make sure they satisfy the project’s general security requirements.
- Requirements for the development team
At this stage, we present the scope of work to our team members. A business analyst creates a product development backlog based on functional and non-functional requirements and business needs. This formalizes the product vision into the project scope for the development team.
Meanwhile, our development team prepares for the actual development. This includes transferring technical knowledge from the solution architect to the development team, creating a testing strategy, reviewing technical documentation, and performing initial project setup of all required environments.
Development phase
Each feature passes through two stages of development:
- Implementation
At this stage, the design is turned into code. We keep an eye on the quality of our products. So in addition to implementing the UI design, our developers conduct regular technical audits and test developed functionality.
- Testing
When developers implement a feature, we test it, validate it, and register defects. For complex systems, we also activate automatic testing. After getting QA and Automation Testing Quality Control (ATQC) reports describing all defects, our developers fix them until the product meets the requirements and works smoothly.
As a rule of thumb, we apply the Scrum methodology to our development process, which divides the whole scope of work into sprints. Sprints at Yalantis last two weeks, during which time we develop the particular part of the application defined in the sprint backlog. So instead of deploying the whole application at once, we work iteratively. At the end of each sprint, we deploy features developed during the sprint.
Thanks to this approach, you can see the results of our work every two weeks instead of waiting till the end of development. This helps us get feedback on developed functionality and correct the project plan to be sure the app meets your expectations.
Read also: Testing and Quality Assurance at Yalantis

Release
To be sure everything will work smoothly after deployment, we move to stabilization. At this point, we make a backup so we won’t lose data in case of an emergency. Then we conduct verification testing.
An integrated software development methodology and testing environment, as well as a production server, are crucial for successful stabilization and deployment. Our DevOps engineers set up this environment. After that, developed and accepted functionality is sent to the integrated development and testing environment.
Finally, the moment has come – your app is ready to meet its end users. Sometimes, a product may first be released to a limited audience for beta testing and be tested in a real business environment. This is called user acceptance testing, or UAT.
Post-release support phase
We offer post-release product support services that enable you to enhance and upgrade your web or mobile app after its official release. With this service, you’ll be sure you can quickly make changes to your product if you suddenly come up with a great new feature or start receiving feedback from users on how to improve your app.
Development lifecycle adjusted to your needs
There are three SDLC frameworks at Yalantis:
Adaptive SDLC
This is the most widely used model and is ideal if you want to release your product as fast as possible.
Adaptive approaches focus on rapid delivery of business value in short iterations in return for a higher degree of uncertainty regarding the overall delivery. This SDLC framework is useful when taking an exploratory approach to finding the best solution or for incremental improvement of an existing solution.
With an adaptive SDLC, the software development framework can start before the end of the discovery phase and be implemented in parallel with it. All functionality is estimated in small portions and taken for work after your approval.
For this framework, completing the project within the budget and timeline is crucial, so we take responsibility for delivering the project on time and fitting into the budget.
This approach allows us to make changes to the project in case your requirements change or you want to alter existing functionality. But if there are significant changes to the product, we determine which functionality can be replaced to fit the budget.
The project manager is responsible for keeping the project within the budget constraints. Nevertheless, the budget needed to implement complete product requirements rises incrementally. When a new portion of requirements are created and mockups are attached to the project and approved by the client, the development team goes through grooming sessions and gives an estimate for fulfilling those requirements, based on which the whole project budget is then estimated.
When an adaptive SDLC isn’t applicable
It’s worth mentioning that an adaptive SDLC framework should not be chosen when:
- The project cost must be fixed before the development phase begins
- The client does not have the opportunity to be involved in the project on a daily basis

Incremental SDLC
This type of SDLC is used in several cases:
- You have strict budget constraints for the project.
- You already know the requirements for the increment and do not plan any changes.
- The product already exists and your main goal is to make changes, add new functionality, or improve existing features. In this case, additional technical research will be included in the discovery phase.
With this model, you’ll know the exact cost of development for the immediate increment. There are several things you should be aware of:
- This framework freezes the backlog of tasks for the current increment before the start of the development phase. If you want to make changes after that point, we’ll negotiate an additional budget with you. However, we do not apply the strict change management approach to the following increment’s discovery phase. Until the discovery phase is finished, the increment’s scope can be adjusted to fit your needs. However, as soon as the increment enters the development stage, no changes in requirements are allowed. All changes and clarifications (which are not set out in the documentation) are taken into work only after an additional agreement is signed and appropriate funding is provided.
- The development phase starts only after the discovery phase. Our developers wait for an accurate estimate of the current increment and get started after that.
- The budget is formed for each individual functionality and may be revised in case of changes to requirements. With this model, changes will be added to the scope of work for the next sprint.
When an incremental SDLC isn’t applicable
The incremental model isn’t applicable when there are a lot of changes in the scope (all changes will go through the change management system, which means additional agreements and a budget approval process).

Augmented team model
This is a common model that’s used when you already have a streamlined development process and want to extend your existing development team with a few of our professionals. In this case, we fully integrate into your SDLC and implement the technical solution proposed by you. This gives you flexibility to work out the requirements for your product.
We also use the augmented team model for post-release support. In this case, the whole scope is unknown and will be formed on demand.
Some important points when considering this approach:
- The project is managed on the client’s side
- The client just needs a team extension
- The Yalantis team is fully integrated into the client’s team
With the augmented team model, work is carried out according to the principle that the changelog is equivalent to the backlog. This gives the team the flexibility to work out and change the requirements for the product being developed. Responsibility for change management and budget management in this context rests entirely with the client.
Who manages the process?
We provide a project manager whose responsibility it is to make you feel as if we’re next door. The project manager organizes development teams and collaboration between developers and describes developers’ tasks in detail. This allows us to streamline the development process and coordinate it efficiently without your having to spend time on that.
During development, the project management team ensures successful implementation of the project in each of its phases, follows the plan developed in terms of timelines, deliverables, budget, and risks, and manages communications and day-to-day operations.
Your project manager is your single point of contact. You have no need to get into the details of the development process and worry about how the project runs.
Let’s talk about other roles besides the project manager that are involved in development.
Team roles
The multi-layered development process requires a diverse team of specialists to ensure the quality of the final product.
Development team
The development team is the core of the product creation process. It consists of full-time and part-time employees and creates the product that was designed by the solution architect, business analyst, and UI/UX designer. The development team is managed by DevOps engineers, who are responsible for bringing together the team’s work.
Roles different specialists play in the project:
Delivery manager
The delivery manager establishes development processes to make sure the result meets the client’s expectations and requests. Their responsibilities include:
- selecting and setting up the most effective delivery method and lifecycle model (data lifecycle management)
- ensuring the effectiveness of the project team structure
- facilitating the successful integration of the company’s consulting and solution development services to meet the client’s business goals
Engagement manager
The engagement manager is responsible for engaging new leads and converting them into contracts. Their responsibilities include:
- eliciting high-level requirements and providing briefs to technical teams
- providing clients with preliminary estimates and clarifying scopes and expected budgets
- participating in client/team interviews and discussions
Solution architect
The solution architect’s duties mainly consist of:
- designing the product’s architectural vision
- creating and defending technical solutions for the assigned business task
- resolving technical problems
Business analyst
The business analyst is responsible for:
- gathering business requirements
- designing the product vision
- creating the product roadmap
- managing a plethora of documentation-related duties
Other specialists include:
- Customer success manager — guides business relationships with customers and resolves potential communication issues
- User interface/user experience (UI/UX) designer — determines the structure of the interface and its functionality and creates its look and feel
- Quality assurance engineer — responsible for ensuring that the solution meets business requirements and is free of errors and defects
- Release manager — accountable for planning release windows and cycles across portfolios and components as well as for managing, planning, and negotiating all release activities
- Security team — ensures the secure architectural vision of the created product and detects vulnerabilities
- Automated testing engineer — responsible for running repetitive and regression tests that require constant iterations due to frequent code changes in order to optimize testing that otherwise would consume a large percentage of test resources
How we ensure app development visibility
There are three pillars of visibility at Yalantis:
- Communication. We provide our clients with deliverables to ensure constant communication during the development process. One of them is a kick-off meeting where a sales representative introduces team members and their roles. During this meeting, we also discuss project tasks, expectations, and aims. In addition to regular calls, you can request a call whenever you have a question about the project or want to make minor changes.
- Progress tracking. Your project manager will document our progress in detail in a project plan document. Thanks to this document, you can always know what possible risks may stall development, how to eliminate these risks, what part of the project has already been developed, and what features are still waiting to be developed. Typically, we send a project plan at the end of each sprint, but you can request it at any time.
- Full access. We give you access to the tools we use, such as Jira, Confluence, and Google Drive as well as any other specific tools required by the project. You can always talk to our developers via several communication channels.
The goal of our app development models is to create a great product by providing quality services to our clients. Thanks to our SDLCs, we can provide visibility over development, predictable delivery, and highly organized processes. All these are essential parts of a high-quality technical solution.
Ready to work with us?
We have what it takes to create an effective solution for your business needs.
About the author