


Over the past year, we’ve been seeing the same type of embedded project come up more often. The requests clients bring to us sound like this:
“We need a camera that counts insects without sending video anywhere.”
“We need a sensor on the motor that warns us when vibration patterns change.”
“We need to detect abnormal sounds in machinery, even when connectivity’s unreliable.”
Different industries, different devices. But all these requests ask for one same thing: running ML models directly on tiny, resource-limited hardware.
That’s what tinyML for edge IoT is all about.
In this article, we dig into why the TinyML approach is becoming more common, and what it takes to build TinyML systems in production.
TL;DR: TinyML as ultra-low power AI
Edge AI, tinyML, and the efficiency it brings
Edge AI/ML is about running machine learning models directly on devices (cameras, sensors, or machines) instead of sending raw data to the cloud. TinyML sits within this space. It’s when you run ML models on resource-limited hardware, like microcontrollers (MCUs) and low-power IoT sensors.

As cloud and powerful edge compute are getting more expensive, moving machine intelligence down to tiny devices becomes economically attractive. TinyML brings even more efficiency across cost, power, and latency.
Instead of streaming data to the cloud, a TinyML model processes it locally on device, near the sensor, often with only a few hundred kilobytes of memory available. This reduces energy consumption, avoids constant connectivity, and enables much faster responses. Because the data doesn’t have to leave the device, this approach can also improve privacy in sensitive environments.
“Not long ago, most ML processing had to happen in the cloud because edge devices simply didn’t have the power. With Edge AI and TinyML, we can now run useful, high-quality logic directly on the device. And do it fast.”

– Mykhailo Maidan, CTO at Yalantis
TinyML applications are most useful when decisions need to happen immediately and on-site, and where relying on gateways or cloud round-trips would be too slow, expensive, or unreliable.
In practice, this includes use cases like:
- IoT sensors detecting early signs of equipment failure for predictive maintenance
- Environmental and agricultural sensors analyzing conditions directly in the field
- Wearable devices monitoring signals in healthcare settings
- Low-power cameras flagging activity or changes locally
Across industrial IoT, healthcare, agriculture, smart home, and environmental monitoring, TinyML makes it possible to add basic intelligence to devices that were previously limited to simple rule-based logic, without the overhead of cloud infrastructure.

Engineering challenges that come with TinyML
The efficiency of TinyML embedded systems comes with a cost. Running tinyML for IoT devices and other low-power hardware means operating under strict physical limitations:
- Limited Flash storage: only tens of KB to a few MB
- Tiny RAM: kilobytes instead of gigabytes
- Limited compute capability: Tens to hundreds of MHz range with no GPU.
- Tight power budgets: Microwatts or milliwatts. Devices are often battery-powered or energy-harvesting
- Limited or no operating system support: Often bare-metal
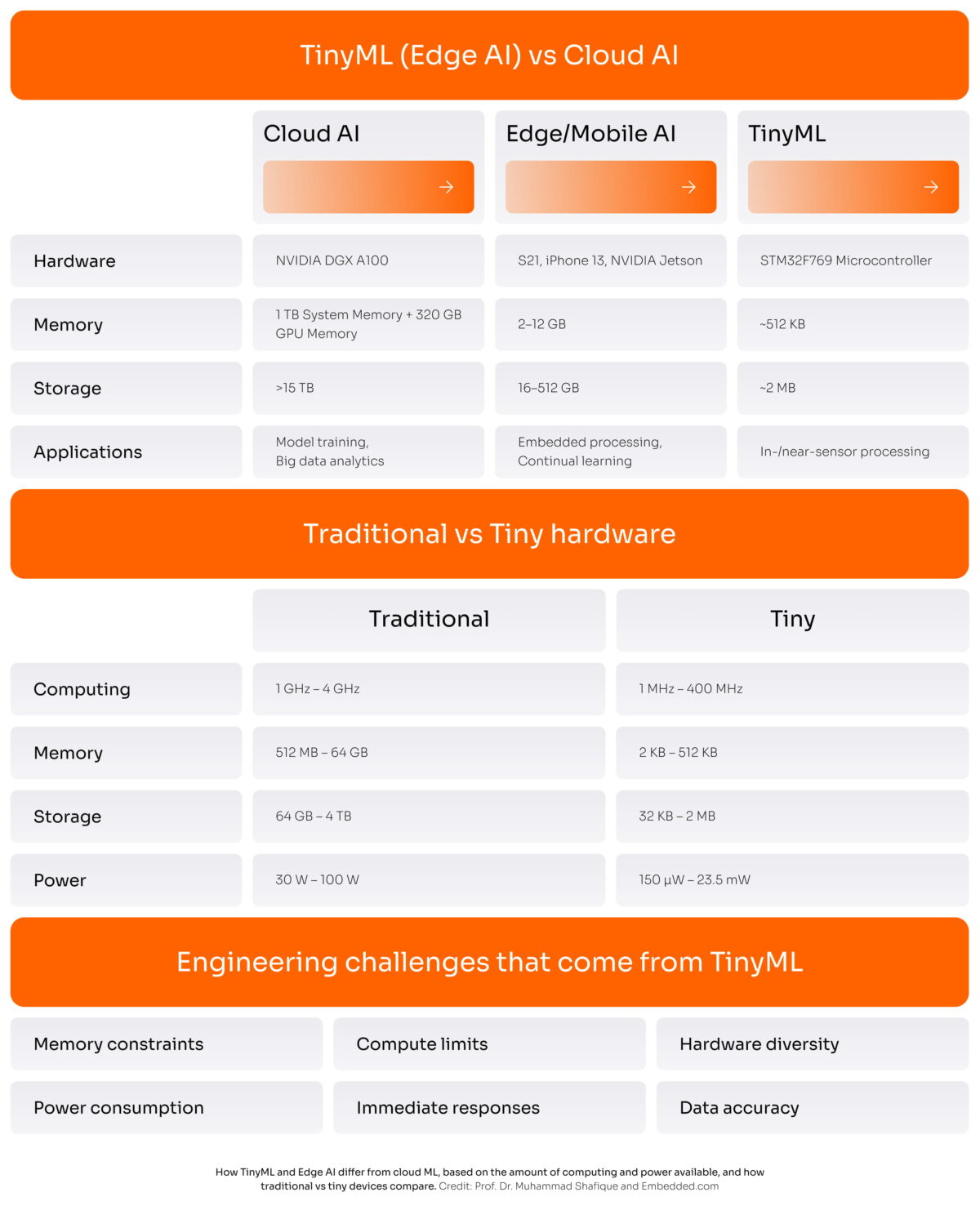
These constraints are not edge cases, but the baseline for TinyML. That’s why TinyML projects involve constant engineering trade-offs. They have to balance accuracy, latency, power consumption, and reliability on hardware that was never designed for heavy computation.
What engineering challenges the constraints of MCUs and IoT devices create:
- Models must be designed to fit memory first
- Power consumption becomes a product requirement
- Compute limits restrict model complexity
- Real-time behavior must be predictable
- Hardware diversity complicates deployment
- Data quality becomes critical
Models must be designed to fit memory first
With only kilobytes of RAM available, model size is a hard constraint, not something engineers can optimize later. If a model doesn’t fit into the device’s memory, it simply won’t run. Engineers have to consider not only the model itself, but also the memory it uses during inference. This includes temporary data and intermediate results.
We see this most clearly in use cases like predictive maintenance. Case in point: battery-powered vibration sensors that detect abnormal patterns locally. The TinyML model must fit entirely into the MCU’s memory while leaving space for firmware and sensor logic. Otherwise, on-device inference fails at runtime or the system becomes unstable. It rules out standard model architectures and forces teams to simplify or redesign models specifically for the target hardware.
Power consumption becomes a product requirement
In TinyML applications, power consumption sets hard limits on what the product can do. TinyML devices are often expected to run for months or years without maintenance. If the device doesn’t meet its expected lifespan, the ML feature isn’t viable, regardless of model performance.
Case in point: remote environmental sensors that classify events such as movement, sound, or threshold changes and transmit only alerts. Because these devices run on small batteries or energy harvesting, teams have to carefully limit how often inference runs, simplify models, or redesign the system so ML is triggered only when necessary. Otherwise, the device fails to meet its expected lifetime in the field.
Compute limits restrict model complexity
Microcontrollers offer only a fraction of the processing power available on typical edge AI devices. This determines which model architectures are viable at all, not just how fast models run.
We see this most often in wearable devices, for example, the ones that analyze audio or environmental signals in real time like hearing aids. These systems need to recognize sounds or events instantly while running on hardware with extremely limited compute capacity and strict power budgets. In this context, standard deep models are impractical.
Instead, teams rely on lightweight model architectures, simplified processing pipelines, and careful feature extraction to keep inference fast and predictable. Otherwise, detection becomes too slow or inconsistent for real-world use, which defeats the purpose of on-device intelligence in wearables.
Real-time behavior must be predictable
Many TinyML systems operate in real-time environments where delayed responses are unacceptable. For example, this is critical for safety modules near industrial machinery that detect presence in restricted zones. Alerts must trigger immediately and reliably on the device itself. This forces teams to design models and pipelines with tightly bounded execution time, control input sizes, and validate timing directly on the target hardware. If inference timing varies, the system becomes unsafe in real-world operation.
Hardware diversity complicates deployment
TinyML solutions often rely on vendor-specific stacks such as STM32 with Cube.AI, NXP MCUs with eIQ, or similar AI-oriented platforms. While these ecosystems make on-device ML feasible, each comes with its own toolchain, model conversion flow, and runtime constraints. A model that runs efficiently on one platform may require adjustments on another.

This becomes especially visible in production scenarios like predictive maintenance deployed across multiple sites. When different factories use different TinyML-ready MCU families, teams often need to retune models, adjust memory allocation, and adapt firmware integration for each target. Over time, deployment and maintenance effort grows with every supported hardware platform.
Data quality becomes even more critical
When real life differs even a bit from training data – a sensor is mounted slightly differently, weather changes, vibration levels shift – ML models can start making wrong predictions.
Standard models can deal with that variation. Tiny ML models can’t.
That’s often the case with agricultural sensors deployed in the field to monitor activity or conditions. Models trained on clean lab data often fail once exposed to weather, terrain, and installation differences. As a result, teams have to collect data from real deployments, retrain models for specific conditions, and validate performance on the target hardware. Otherwise accuracy drops sharply in production.
So what does TinyML require from the engineering approach?
For TinyML, decisions about memory, power, compute, and data are tightly coupled, and optimizing one often comes at the expense of another.
In practice, this means successful TinyML projects depend less on individual techniques, and more on how the project is approached from the start.
Based on our experience building production-ready firmware and edge ML systems, a few principles consistently make the biggest difference.
How we recommend approaching TinyML projects
Over the past year, we’ve seen a steady increase in TinyML projects. Below are the core guidelines we follow.

Get training data from a real environment
Before choosing TinyML models or frameworks, you need to collect as much data from the real environment as possible. For example, if your system is meant to detect or count insects using a camera, get training data from that exact camera and deployment setup, including its mounting position, distance to the target, lighting conditions, and typical background. Images collected in controlled conditions or from public datasets often fail to reflect lighting, angles, and background noise in the real environment.
Avoid general-purpose hardware
TinyML performance, cost, and feasibility depend heavily on hardware choices. General-purpose MCUs are often inefficient, while AI-aware chips with accelerators are increasingly available – and far better suited for tinyML applications.
As ML adoption on low-power devices grows, more chip manufacturers are designing microcontrollers specifically for on-device ML. One example is STMicroelectronics, which introduced the STM32N6 chip with a dedicated neural accelerator for running TinyML models directly on the device. These chips can execute ML workloads in hardware, making inference faster, more power-efficient, and more cost-effective.

“More and more chip manufacturers, like STM and NXP, are adding dedicated hardware accelerators for ML. They’re cheaper, faster, and more efficient, and it’s an opportunity teams should take advantage of.”
– Mykhailo Maidan, CTO at Yalantis
Rely on proven tooling
On low-power devices, instability, poor documentation, or weak hardware integration quickly call for deployment and maintenance problems. That’s why we advise teams to choose tooling that’s well-supported, predictable, and tightly aligned with the target hardware.
In practice, this means avoiding a single “universal” TinyML framework and selecting tools based on the target hardware and the type of workload you’re deploying instead.
-
Start with vendor-native tooling for deployment
For TinyML embedded systems, we recommend starting with vendor-native toolchains.
For example: when working with STM32-based hardware, we use and recommend STMicroelectronics STM32Cube.AI. For NXP platforms, we rely on eIQ® AI Software Development Environment.
These toolchains are built specifically for their chips. They make it easier to fit models into memory, use available hardware accelerators, and meet power and latency constraints. In our experience, this reduces risk compared to deploying TinyML models through hardware-agnostic ML framework alone.
-
Use general-purpose frameworks for well-supported tasks
We often use TensorFlow Lite (Google’s open-source ML framework), especially for image classification and object detection tasks where the ecosystem is mature and well-supported. TFLite provides a strong foundation for training, model optimization, and conversion, and works well for vision-related workloads on constrained devices.
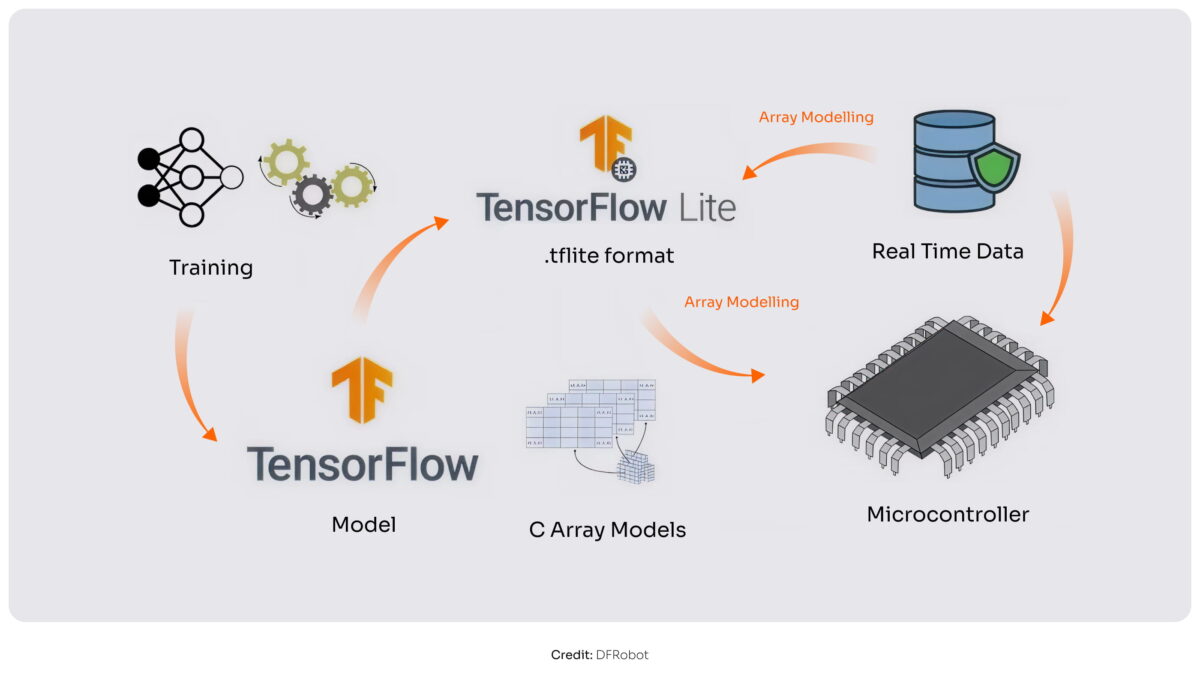
In practice, TFLite is used to train, convert, and prepare the model, but the final step of putting that model onto a device is handled by the chip vendor’s tools. Most production TinyML deployments today run on Arm Cortex-M–based microcontrollers. Vendors like STMicroelectronics and NXP provide tooling that integrates TFLite models into their hardware ecosystems.
Other lightweight libraries like uTensor, can also be viable. It was designed for rapid prototyping and research, complementing the more production-focused TFLite.
- Use end-to-end ML platforms to validate tinyML use cases
Using platforms like Edge Impulse can be very effective in the early stages of TinyML projects. They simplify data collection from sensors, and we often recommend them when teams need to quickly collect data, prototype models, and validate whether a TinyML approach is viable at all. However, before moving to production, you still need to validate that the resulting models fit the target hardware, meet power and timing requirements, and can be maintained and updated over the device’s lifetime:
- Does the generated model fit into flash and RAM?
- Does inference run within timing limits on the actual MCU?
- Can the device still meet its expected lifetime?
Consider selective use cases
Last but not least, TinyML is a best suited approach for specific, critical tasks. It delivers the most value when decisions must be made locally. For example, when low latency, low power consumption, or offline operation are essential. In many cases, the most effective setup combines traditional embedded logic with a small, well-scoped ML component. This keeps systems simpler, more reliable, and easier to maintain.
TinyML often acts as an enabler. A small ML model can filter events, detect relevant patterns, or trigger heavier processing only when needed, reducing unnecessary computation and data transfer.

We often see the selective use of TinyML pay off in computer vision projects. Adding a lightweight ML model to an existing vision pipeline can improve accuracy without redesigning the entire system. In some cases, we saw targeted ML enhancements increase detection accuracy from around 80% to 90% or higher – provided the model was trained on real data and matched to the available hardware. For object detection, this may involve using models such as YOLO, but only when the hardware and constraints allow it.
Would TinyML applications be relevant for you?
Consider starting a tinyML project if most of these are true:
- The device needs to make decisions locally, without relying on the cloud
- Latency matters (responses must happen immediately)
- The system runs on a battery or energy harvesting and must minimize power usage
- Connectivity is limited, expensive, or unreliable
- You need to classify, detect, or filter events rather than process all raw data
- You’re improving or augmenting an existing pipeline (e.g. boosting accuracy, reducing false positives)
- You have access to real-world data from the actual device and environment
The Edge AI future is tiny (and it’s already here)
So, how’s this? ML models can now run on sub-milliwatt microcontrollers, which turns AI from a cloud-only capability into a built-in feature of sensors and everyday products.
Instead of sending raw data upstream, edge devices can detect patterns, filter signals, and react locally. This enables faster responses, lower power use, and systems that work even without constant connectivity.
At Yalantis, we’re already helping our clients build these systems, combining embedded engineering, TinyML, and edge AI to cover the right use cases, on the right hardware, with the right tooling. Want in?


