


Once, during an introductory meeting on a client’s site, our engineers saw a maintenance team spend 3 hours disassembling a perfectly functioning gearbox.
The preventive maintenance schedule said it was time for service at 10,000 operating hours, so out came the wrenches. Two technicians, $1,200 in labor, $800 in parts that didn’t need replacing. The gearbox had another 3,000 hours of life left, easily.
Meanwhile, fifty yards away, a conveyor motor was overheating, throwing off abnormal vibration patterns that any decent sensor would have caught. That motor failed catastrophically two days later. Production stopped for eighteen hours.
This happens every day in facilities across North America and Europe. We waste money replacing components that still work while simultaneously missing the failures that actually matter. The problem is not that maintenance teams lack skill or dedication. The problem is that we force them to make decisions without the information they need. Traditional maintenance operates blind, relying on either fixed calendars or crisis response, both of which ignore what the equipment itself is trying to tell us.
Predictive maintenance programs offer that alternative. While monitoring equipment condition in real time and using data to forecast failures before they occur, companies can schedule repairs when they make economic sense rather than when a crisis demands them. The evidence supporting this approach has grown compelling. An MIT study tracking heavy-duty truck fleets found that predictive maintenance reduced total maintenance expenditures by $240 to $480 per vehicle annually, capturing 85% of all achievable cost savings through improved decision-making.
This article provides a practical framework for launching a predictive maintenance program, from initial assessment through full-scale implementation. The guidance draws from real-world deployments across manufacturing, logistics, and industrial operations where predictive approaches have replaced reactive firefighting with systematic, data-driven maintenance strategies.
What is a Fleet Predictive Maintenance Program?
A predictive maintenance program uses real-time equipment data to identify developing problems and predict when failures will occur. Unlike preventive maintenance that follows fixed schedules regardless of actual equipment condition, predictive programs respond to what the data reveals about each specific asset.
The core principle involves continuous monitoring. Sensors track vibration patterns, temperature changes, pressure fluctuations, oil quality, and dozens of other parameters that indicate equipment health. When measurements deviate from normal operating ranges, the system flags potential issues. Machine learning models then analyze these patterns to estimate remaining useful life and recommend optimal intervention timing.
Consider a fleet of delivery trucks. Traditional preventive maintenance might replace transmission fluid every 50,000 miles whether the fluid needs changing or not. A predictive approach monitors fluid condition directly through sensors that detect contamination and degradation. When the data shows the fluid has deteriorated beyond acceptable limits, the system triggers a maintenance alert. The truck gets serviced based on actual need rather than arbitrary mileage intervals.
Key Components of a Predictive Maintenance Program
Before diving deep into the predictive maintenance process set up, we should understand its necessary components and, obviously, check their actual status (or existence) before launching a pilot program.
Data Acquisition Infrastructure
The foundation of any predictive program requires sensors that capture equipment condition data. Modern industrial assets often come equipped with built-in sensors monitoring dozens of parameters. For older equipment, retrofitting with external sensors provides the necessary data streams. The key involves identifying which measurements actually predict failures rather than simply generating noise.
IoT and Sensor Networks
The Industrial Internet of Things has dramatically reduced the cost and complexity of sensor deployments. Wireless sensors eliminate expensive cabling requirements. Battery-powered devices can operate for years without maintenance. Standardized communication protocols allow mixing sensors from different manufacturers. This accessibility has made comprehensive equipment monitoring economically viable even for mid-sized operations.
Analytics Platform
Raw sensor data means nothing without interpretation. The analytics layer processes streaming data, identifies anomalies, and generates failure predictions. This typically combines statistical analysis to establish normal operating ranges with machine learning models trained to recognize patterns that precede specific failure modes.
Cloud versus Edge Computing
Processing sensor data requires computational resources. Cloud platforms offer unlimited scalability and centralized management but depend on reliable connectivity and introduce latency. Edge computing devices process data locally at or near the equipment, enabling faster response and reducing bandwidth requirements. Hybrid architectures often make the most sense, with edge devices handling real-time monitoring and immediate alerts while cloud systems perform deeper analysis and manage fleet-wide optimization.
Integration Systems
Predictive insights only create value when they connect to existing workflows. Maintenance work order systems, spare parts inventory, and scheduling tools must receive alerts and recommendations automatically. Technicians need predictions delivered in formats that support their daily decision-making rather than requiring them to check separate dashboards.
Organizational Processes
Technology alone does not make a program successful. Teams need clear protocols for responding to alerts, evaluating recommendations, and documenting outcomes. The feedback loop between predictions and actual results allows continuous improvement in model accuracy.
Is your data infrastructure ready for predictive maintenance?
Let’s assess your sensors, networks, and systems to build a successful program.
Benefits of Implementing a Predictive Maintenance Program
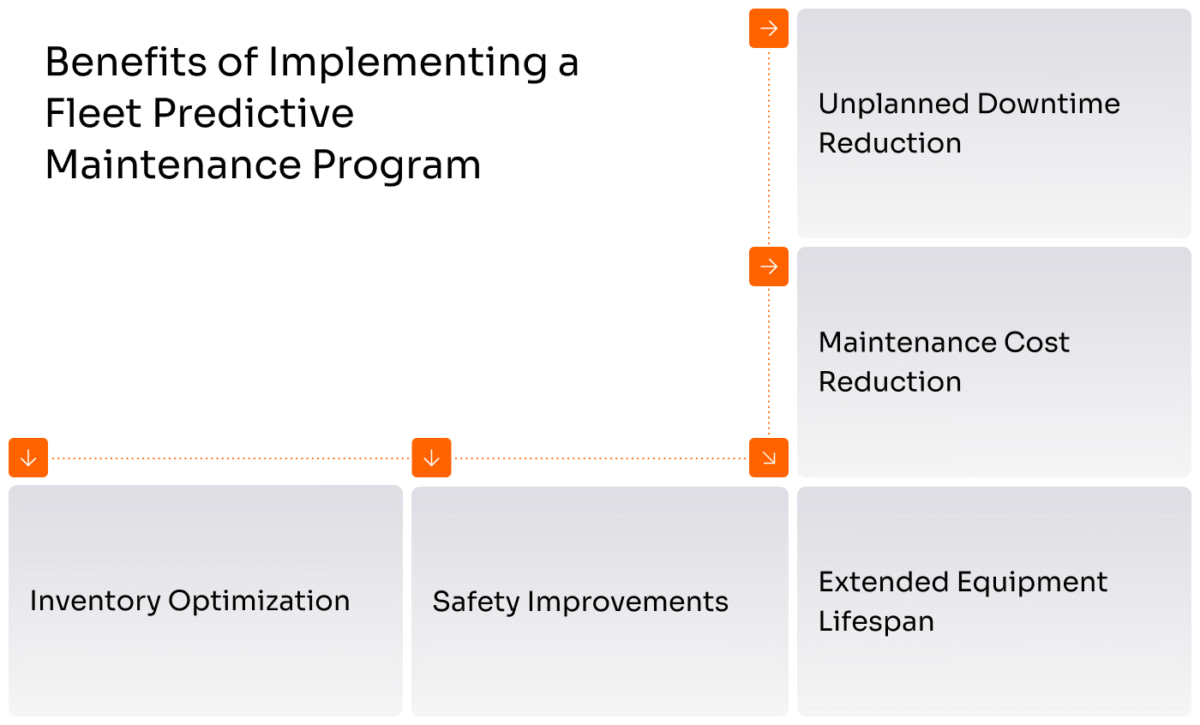
The financial case for predictive maintenance extends well beyond avoiding catastrophic failures. Research across multiple industries has documented specific, measurable improvements that directly impact the bottom line.
Unplanned downtime represents the most visible cost that predictive programs address. When a production line stops unexpectedly, the direct costs include emergency repair labor, expedited parts shipping, and lost production. The indirect costs often exceed these direct expenses. Manufacturers miss delivery commitments and pay penalties. Warehouse operations lose throughput during peak season. Fleet operators strand drivers and disappoint customers. Studies indicate predictive maintenance can increase asset uptime by 10 to 20 percent simply by preventing these unplanned stoppages.
Maintenance spending itself decreases under predictive approaches. Technicians stop replacing components that still function properly just because they reached a scheduled interval. They also avoid the expensive premium for emergency service calls. The MIT trucking study found that predictive approaches reduced unnecessary repairs far more than they prevented breakdowns. Technicians equipped with accurate condition data stopped overestimating failure risk and performing costly interventions on equipment that did not require immediate attention. Total maintenance costs decreased 15 to 30 percent compared to reactive and preventive strategies.
Equipment lifespan extends when problems get caught early. A bearing showing early signs of wear can be replaced during regular service. Ignore the warning and that bearing damages the shaft, the housing, and surrounding components. What would have been a $500 repair becomes a $5,000 rebuild. Predictive monitoring allows addressing small problems before they cascade into major damage. Assets run 20 percent longer when maintained based on actual condition.
Safety improvements accompany the operational and financial benefits. Equipment failures in industrial settings create hazards for workers. A failing conveyor belt in a warehouse, an overheating motor in a manufacturing plant, or a brake system problem in a commercial vehicle all pose risks beyond the economic damage. Catching these issues early protects both employees and the company from the consequences of safety incidents.
Inventory management becomes more strategic with predictive data. Instead of stockpiling parts to buffer against unpredictable failures, maintenance teams can order components when predictions indicate upcoming need. This reduces working capital tied up in spare parts inventory by 20 to 50 percent while actually improving parts availability when service is needed.
Steps to Start a Predictive Maintenance Program

Launching a predictive maintenance program requires systematic planning rather than simply installing sensors and hoping for insights. Organizations that treat implementation as a structured project achieve results faster and avoid common pitfalls.
Step 1: Assess Equipment and Data Requirements
Begin by identifying which assets matter most to operations. Not every piece of equipment justifies the investment in predictive monitoring. Focus on assets where unexpected failure creates significant consequences, either through production loss, safety risk, or repair cost.
For each critical asset, document the primary failure modes. Manufacturing equipment might fail through bearing wear, motor overheating, or hydraulic leaks. Fleet vehicles experience engine problems, transmission issues, and brake system degradation. Understanding what typically goes wrong guides sensor selection and model development.
Evaluate existing data sources before installing new hardware. Modern equipment often includes onboard diagnostics and sensors that generate relevant data. Industrial control systems, vehicle telematics, and enterprise asset management platforms may already capture information useful for predictive analysis. Reviewing this existing data infrastructure prevents duplicating capabilities and reveals gaps that require new sensors.
Step 2: Choose Predictive Maintenance Tools and Technologies
The technology stack for predictive maintenance includes three main categories: sensors for data collection, platforms for data processing and analysis, and integration tools that connect predictions to maintenance workflows.
Sensor selection depends on the specific failure modes being monitored. Vibration sensors detect bearing problems and motor imbalance. Temperature sensors identify overheating in electrical systems and friction in mechanical components. Oil analysis sensors monitor fluid degradation. Pressure sensors reveal leaks and system inefficiencies. The goal involves deploying sensors that provide early warning for the most consequential failure types.
Analytics platforms range from simple statistical monitoring to sophisticated machine learning systems. Early programs often start with threshold-based alerts that trigger when measurements exceed normal ranges. More advanced implementations employ machine learning models that recognize complex patterns across multiple sensors and predict specific failure types with estimated timing.
Consider whether to build analytics capabilities internally or partner with specialized vendors. Developing machine learning models requires data science expertise and significant historical data for training. Many organizations lack both resources initially. External providers bring pre-trained models and domain expertise that accelerates implementation, particularly for common asset types like industrial motors, HVAC systems, or vehicle engines.
Step 3: Set Up the Program and Workflow
A successful predictive maintenance process flow requires coordinating data collection, model deployment, and alert delivery. Sensors need reliable connectivity to transmit data to analytics platforms. Cloud-based systems offer scalability and remote access but require addressing data security and bandwidth considerations. Edge computing approaches process data locally, reducing transmission requirements and improving response times.
Define clear workflows for alert handling. When the system predicts a failure, who receives the notification? What evaluation process determines whether to act immediately or schedule intervention during planned downtime? How do technicians document their response and the actual equipment condition found? These protocols prevent alerts from being ignored and ensure the system learns from feedback.
Integration with existing systems determines whether predictions drive action or get overlooked. Automatic work order creation in the maintenance management system, spare parts reservation in the inventory system, and scheduling adjustments in the operations calendar all increase response rates. The easier you make it for teams to act on predictions, the more value the program delivers.
Step 4: Train Staff and Establish Processes
Maintenance technicians bring decades of experience reading equipment behavior through sound, vibration, temperature, and performance. Predictive systems augment rather than replace this expertise. Effective training helps technicians understand what sensors measure, how algorithms generate predictions, and when to trust the system versus their own judgment.
Explain the reasoning behind predictions rather than treating the system as a black box. When an alert indicates bearing wear, show technicians the vibration frequency patterns that triggered the warning. When the model predicts a coolant leak, display the temperature trends and pressure readings that support the diagnosis. This transparency builds trust and helps technicians provide better feedback on prediction accuracy.
Create documentation that supports consistent execution. Checklists for responding to specific alert types ensure thorough investigation. Templates for condition reports capture observations that improve model training. Standard procedures for escalating uncertain situations prevent both overreaction and dangerous neglect.
Step 5: Monitor Performance and Iterate
Predictive maintenance programs improve through continuous refinement based on actual results. Track how often predictions correctly identified failures, how many false alarms occurred, and how much advance warning the system provided. This performance data guides adjustments to sensor selection, alert thresholds, and model parameters.
Document cases where failures occurred without prediction. These represent blind spots in the monitoring approach. Analysis may reveal missing sensors, inadequate data quality, or failure modes not yet modeled. Each surprise provides information for strengthening the program.
Similarly, investigate false alarms where predictions prompted inspections but revealed no problems. High false alarm rates erode trust and waste maintenance resources. Tuning alert thresholds and improving models to distinguish normal variation from true degradation reduces these disruptions while maintaining genuine problem detection.
From data acquisition to workflow integration.
We build the end-to-end analytics platform you need to predict equipment failure and prevent downtime.
Creating a Predictive Maintenance Plan
A formal maintenance plan provides the framework that transforms technology capabilities into consistent operational practice. The plan should address several key elements that guide daily execution.
Monitoring Frequency
Different equipment types and failure modes require different monitoring cadences. Critical safety systems may need continuous real-time monitoring with immediate alerts. Other assets might be checked hourly or daily. The monitoring frequency should match the speed at which problems typically develop. Bearing failures often show warning signs days or weeks in advance. Electrical failures may progress much faster.
Key Performance Indicators
Establish metrics that measure both technical and business performance. Technical KPIs include prediction accuracy rates, false alarm percentages, and average advance warning time before failures. Business metrics track maintenance cost per asset, unplanned downtime frequency, and repair-versus-replace ratios. Regular review of these indicators guides program improvements and demonstrates value to stakeholders.
Reporting Structure
Define how information flows through the organization. Daily operational reports might highlight current alerts and scheduled interventions. Weekly summaries provide maintenance managers with trend analysis and resource planning data. Monthly executive reports quantify cost savings, uptime improvements, and progress toward strategic goals. A clear reporting structure and a standardized predictive maintenance format for alerts and summaries keep all stakeholders informed and aligned.
Team Roles and Responsibilities
Successful programs require collaboration between maintenance technicians who understand equipment, data analysts who interpret sensor information, and operations managers who balance maintenance needs against production schedules. Document who monitors system alerts, who approves intervention decisions, who performs actual maintenance work, and who analyzes outcomes for continuous improvement. Role clarity prevents delays and ensures accountability.
Escalation Procedures
Not every prediction requires immediate action, but some demand rapid response. Define criteria for escalating high-risk situations. Equipment showing signs of imminent catastrophic failure needs different handling than gradual degradation that can wait for scheduled maintenance. Clear escalation paths ensure critical situations receive appropriate attention without creating unnecessary urgency around routine issues.
How to Measure the Effectiveness of a Predictive Maintenance Program
Demonstrating program value requires tracking specific metrics that capture both operational improvements and financial returns. Several measurements provide insight into how well the predictive approach performs.
Mean Time Between Failures
This metric tracks how long equipment operates between failure events. Effective predictive maintenance should increase this duration as problems get caught and corrected before causing breakdowns. Comparing pre-program and post-program MTBF provides clear evidence of reliability improvement.
Maintenance Cost per Operating Hour
Total maintenance spending divided by equipment operating time reveals efficiency trends. Predictive programs should reduce this metric by eliminating unnecessary preventive replacements and avoiding expensive emergency repairs. Track this separately for labor, parts, and outside services to identify where savings accumulate.

Planned versus Unplanned Maintenance Ratio
The proportion of maintenance work that occurs on schedule rather than in response to failures indicates program maturity. Early programs might see 60% planned and 40% unplanned work. Mature predictive programs often achieve 90% or higher planned maintenance as predictions allow proactive scheduling.
Prediction Accuracy
Monitor what percentage of failure predictions prove correct when technicians inspect equipment. Track both false positives (predictions of problems that did not exist) and false negatives (failures that occurred without prediction). Target accuracy above 70% for most industrial applications, with improvement over time as models learn from more data.

Note, In predictive maintenance, “correct predictions” can be split into:
True Positives (TP): The system correctly predicted a failure that happened.
True Negatives (TN): The system correctly predicted no failure, and none happened.
Unplanned Downtime Frequency
This measures how often unexpected failures occur, which is a direct indicator of how well the predictive program is working.

Key Challenges and Considerations Before Investing in Predictive Maintenance
Organizations implementing predictive maintenance encounter several common obstacles that can derail programs if not addressed proactively.
Predictive models require clean, consistent data to generate accurate predictions. Sensor failures, communication disruptions, and calibration drift all corrupt data streams. Organizations often discover that 30% to 40% of implementation effort goes toward maintaining data quality rather than building models. Budget adequate resources for data infrastructure and establish monitoring to detect problems quickly.
Along with that, most companies operate diverse equipment fleets from multiple manufacturers spanning different ages and technology generations. Creating a unified monitoring approach across this heterogeneity proves difficult. Older equipment may lack sensors entirely. Proprietary communication protocols prevent data access. Budget significant integration effort and accept that comprehensive coverage may require years to achieve.
Experienced maintenance technicians sometimes view predictive systems as threatening their expertise or questioning their judgment. Technicians report that the tools helped them avoid unnecessary work (the most common source of savings) rather than catch problems they would have missed. Frame predictive systems as decision support that makes experienced technicians more effective rather than replacement technology.
Also, there is another catch. Machine learning models need historical failure data for training, but most organizations lack adequate records of failure patterns and precursor conditions. This creates a cold-start problem where programs cannot generate accurate predictions until they accumulate sufficient operational data. Starting with simpler threshold-based monitoring while building the dataset for more sophisticated models provides value during the learning period.
Comprehensive predictive programs require significant upfront investment in sensors, software platforms, integration work, and training. Small and mid-sized operations may struggle to justify the cost without clear ROI projections. This is why starting with a focused pilot on the most critical assets will show value before expanding to full-scale implementation.
A successful PdM program is more than software
We’ll help you build the strategy to tackle data quality, integration, and organizational change.
Launching a Fleet Predictive Maintenance Pilot Program
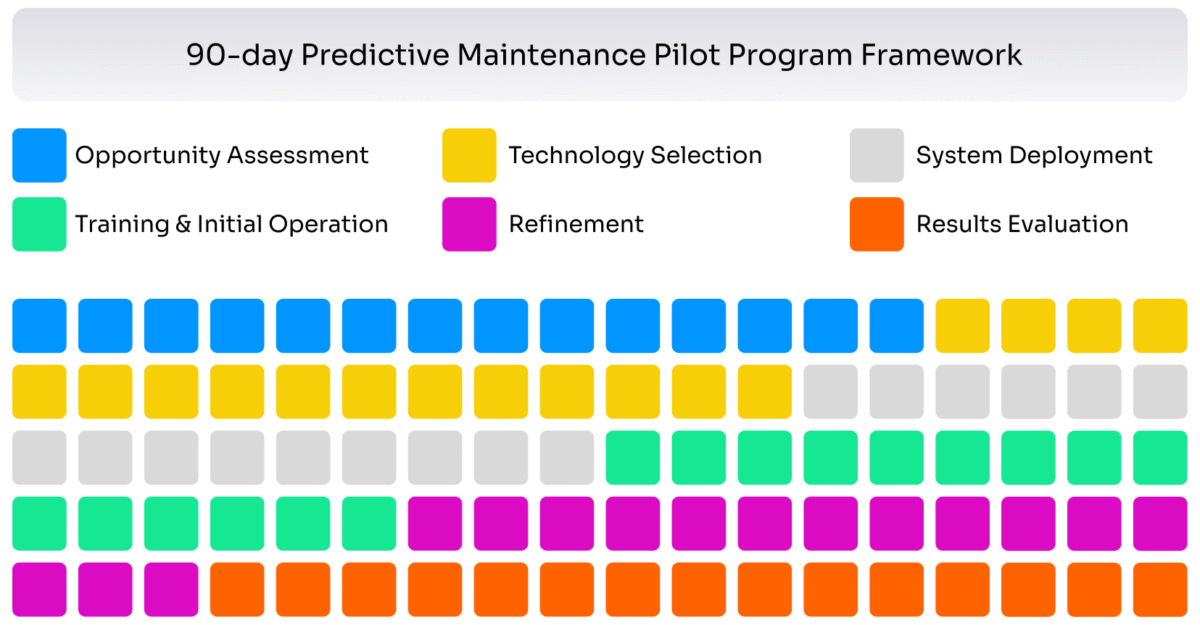
The following 90-day framework illustrates how a logistics company might launch a predictive maintenance pilot for commercial vehicle fleets. This concrete example demonstrates how the concepts discussed above translate into practical action.
Day 1-14: Opportunity Assessment
The maintenance director identifies 50 trucks with the highest operating costs as pilot candidates. Analysis of maintenance records reveals that engine-related failures account for 40% of unplanned downtime and carry the steepest repair costs. The team documents specific failure modes: coolant leaks, oil degradation, bearing wear, and cylinder head problems. They confirm that trucks already collect sensor data through onboard telematics but no one analyzes it systematically.
Day 15-30: Technology Selection
The company evaluates whether to build analytics capabilities internally or partner with a specialized predictive maintenance vendor. Given limited data science resources and the need for rapid results, they choose a vendor that offers pre-trained models for commercial vehicle engines. The vendor’s platform connects directly to the existing telematics system and integrates with the current maintenance management software. Pricing follows a per-vehicle-per-month model that aligns costs with program scale.
Day 31-45: System Deployment
Technicians activate advanced data collection on pilot vehicles, capturing detailed engine sensor data including temperatures, pressures, vibrations, and fluid conditions. The vendor configures alert thresholds based on vehicle specifications and historical data. Integration teams connect the prediction platform to the work order system so alerts automatically create inspection tasks. They establish a daily review process where the maintenance supervisor checks predictions, assigns follow-up work, and documents findings.
Day 46-60: Training and Initial Operation
All technicians complete training on responding to predictive alerts. The vendor explains what sensor patterns indicate specific problems and how confidence levels should guide response urgency. For the first two weeks, the team treats all alerts as inspection recommendations rather than mandatory interventions, building confidence in the system without forcing immediate action. Technicians provide feedback on prediction accuracy and suggest threshold adjustments.
Day 61-75: Refinement
Analysis of the first 30 days of operation reveals that coolant leak predictions achieve 85% accuracy while bearing wear alerts show only 45% accuracy with many false positives. The team works with the vendor to recalibrate bearing monitoring thresholds. They discover that local operating conditions (frequent stop-and-go in urban delivery routes) create vibration patterns the model interprets incorrectly. Adjusting for this context improves performance. Documentation procedures get streamlined based on technician feedback.
Day 76-90: Results Evaluation
The pilot program demonstrates measurable improvements. Unplanned downtime decreased by 12% as predictions caught developing problems before failures occurred. Maintenance costs per vehicle declined by $180 monthly through reduced emergency service calls and better parts planning. The team documented five instances where predictions identified issues technicians would have missed using traditional inspection methods. Based on these results, leadership approves expansion to the full 500-vehicle fleet over the next six months.
This pilot approach follows the engagement model many successful programs employ: prove value on a manageable scale before committing to enterprise-wide deployment. The focused scope allows rapid implementation while generating the evidence needed to justify broader investment.
Conclusion
Predictive maintenance programs represent a fundamental shift from hoping equipment survives until scheduled service to knowing with confidence when intervention makes sense. The technology enabling this shift has matured rapidly. Sensors cost a fraction of what they did a decade ago. Cloud platforms provide unlimited analytical horsepower. Machine learning algorithms detect subtle failure patterns humans cannot perceive. These capabilities combine to deliver documented savings that justify investment across industries from manufacturing to logistics to energy production.
Success requires more than deploying technology. Organizations must integrate predictions into existing workflows, train teams to interpret and act on alerts, maintain data quality, and continuously refine models based on real-world outcomes. The companies seeing the strongest returns treat predictive maintenance as a systematic program, integrating it into their core operations and predictive maintenance business model, rather than as a one-time project.
For companies ready to move forward, starting with a focused pilot on high-value assets provides the safest path. Prove the concept works in your specific operating environment before expanding broadly. Use pilot results to refine technology choices, develop team capabilities, and build organizational confidence. The 90-day framework outlined above provides a template adaptable to most industries and equipment types.
The question facing maintenance leaders today centers not on whether to adopt predictive approaches but on how quickly to make the transition. Equipment continues aging. Failures keep occurring. Costs mount. Every day spent planning represents another day of paying for problems that could have been prevented.
Ready to explore how predictive maintenance could reduce your maintenance costs and improve equipment reliability? Yalantis has helped logistics, manufacturing, and industrial operations deploy successful predictive programs. Schedule a consultation to discuss your specific situation and receive a customized implementation roadmap.
FAQ
What kind of data is needed for a predictive maintenance pilot?
A successful pilot requires at minimum several months of normal equipment operation data including sensor measurements, fault codes, and maintenance records. The most valuable data captures equipment behavior both before and after failures. For fleet vehicles, onboard telematics typically provide 80-90% of necessary data. Manufacturing equipment may require retrofitting additional sensors to monitor critical parameters like vibration, temperature, and pressure. Historical maintenance records that document failure types, symptoms, and corrective actions help train models to recognize warning patterns.
How long should a pilot program typically run before showing results?
Most pilots demonstrate initial results within 60-90 days but require 4-6 months for statistically significant outcomes. The timeline depends on equipment failure rates and operating cycles. Assets that fail monthly provide faster feedback than equipment that fails annually. Early indicators like prediction accuracy and alert response rates become visible within weeks. Cost savings and reliability improvements need longer periods to accumulate meaningful data. Plan to run pilots at least through one complete maintenance cycle to capture seasonal variations and diverse operating conditions.
How much does it cost to implement a predictive maintenance program?
Costs vary widely based on asset type, fleet size, and existing infrastructure. A basic pilot monitoring 25-50 critical assets typically requires $50,000-$150,000 for sensors, software, integration, and consulting support. Enterprise implementations across hundreds or thousands of assets can reach $500,000-$2,000,000 for comprehensive coverage.
How to measure the effectiveness of a predictive maintenance program?
Effectiveness measurement should track both leading indicators (prediction accuracy, alert response time, false alarm rate) and lagging indicators (maintenance cost trends, equipment uptime, failure frequency). Compare metrics before and after implementation to quantify improvements. Key measurements include mean time between failures, maintenance cost per operating hour, ratio of planned to unplanned maintenance, and total cost of ownership. Financial metrics should capture avoided costs from prevented failures, reduced emergency service expenses, optimized parts inventory, and extended equipment life. Most organizations see measurable improvement within six months but achieve maximum value after 18-24 months as models improve and teams optimize processes.
How can I scale a successful pilot into a full predictive maintenance strategy?
Scale based on lessons learned during the pilot rather than simply replicating the approach broadly. Identify which equipment types showed strongest prediction accuracy and highest ROI. Expand coverage to similar assets first before tackling more challenging applications. Standardize data infrastructure, alert workflows, and reporting formats to support enterprise-scale operations. Build internal expertise through training and hiring rather than remaining dependent on external vendors. Integrate predictive capabilities into strategic asset management decisions including equipment selection, retirement planning, and service contract negotiations. Mature programs evolve from preventing failures to optimizing total lifecycle costs across the entire asset portfolio.




